随便记一下,大都常混淆或者易忘基础知识
网站连接重置,用清空缓存和Cookie解决
今天在打buuctf靶场的时候遇到一个问题,就是当页面跳转时,会显示连接重置,导致我的sql注入结果不能显示,然后百度了一下,发现可能是浏览器缓存太多导致的,于是我把浏览器的缓存和cookie一同全部清空,然后我再刷新sql 注入那道题的界面,解决了,没有再显示连接重置,也显示了我的注入结果,我正要交flag的时候,然后,我发现…..,我的buuctf账号下线,我的csdn账号也下线了
cookie的作用和重要性就出来了,从这个事情看出,cookie是当我们登录网站的主要身份凭证,当我删除cookie后,我无法证明自己身份时,即网站当前浏览器无该账号当前在该网站的cookie时,网站就会强制下线我的账号
但是,如果我们在登录网站时(没有退出),点击了其他链接导致自己在该浏览器的该网站的cookie外泄,被有心人获取,那么拥有你的cookie的人,就可以登录你的账号,在你登录的网站上进行修改密码,删除文章,甚至可以转账等等
所以以后登录了一些重要网站时,比如支付宝,淘宝,博客网站时,别随便点击链接,保证自己的信息安全,不要黑客被黑客黑了,那确实有点难为情了
Cookie实际上是一小段的文本信息。客户端请求服务器,如果服务器需要记录该用户状态,就使用response向客户端浏览器颁发一个Cookie。客户端浏览器会把Cookie保存起来。当浏览器再请求该网站时,浏览器把请求的网址连同该Cookie一同提交给服务器。服务器检查该Cookie,以此来辨认用户状态。服务器还可以根据需要修改Cookie的内容
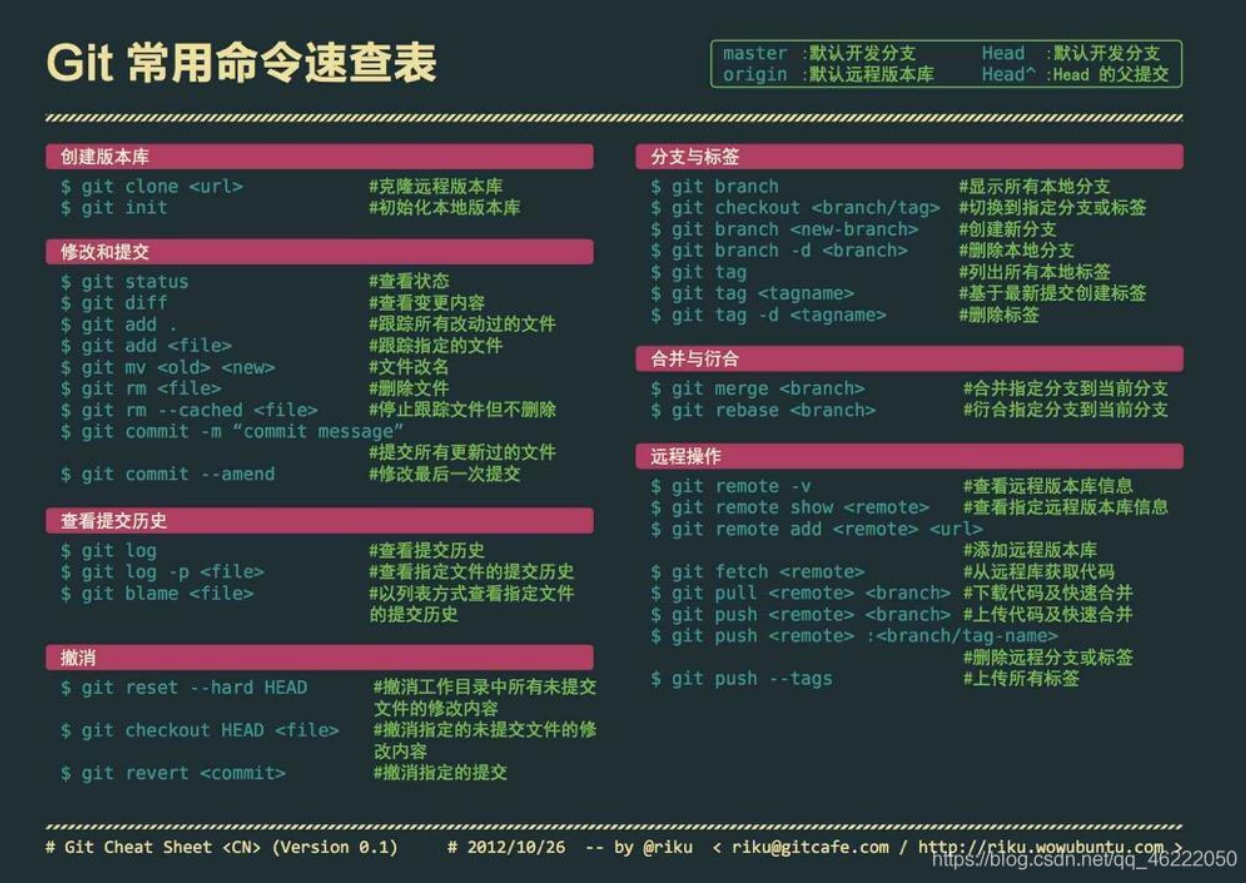
git命令
使用githack,记录一些命令
随手记录题目
头疼的php代码审计
第一眼很头疼的php代码审计,但看着却没有什么太大的考点,这里我没有题目,就在本地试试能不能绕过所有的
1 |
|
本地回环
本地回环地址(
Loop back address),不属于任何一个有类别地址类。它代表设备的本地虚拟接口,所以默认被看作是永远不会宕掉的接口。主要作用有两个:一是测试本机的网络配置,能PING通
127.0.0.1说明本机的网卡和IP协议安装都没有问题;另一个作用是某些SERVER/CLIENT的应用程序在运行时需调用服务器上的资源,一般要指定SERVER的IP地址,但当该程序要在同一台机器上运行而没有别的SERVER时就可以把SERVER的资源装在本机,SERVER的IP地址设为127.0.0.1同样也可以运行。本地回环地址指的是以
127开头的地址(127.0.0.1 - 127.255.255.254),通常用127.0.0.1来表示但是,使用
127.0.0.1/8内的不同地址,就可以在本机上设置侦听相同端口的多个服务器
client-ip和X-Forwarded-For和
1)
client-ip:客户端ip,相较于X-Forwarded-For,它只有一个ip也就是真实ip,当不能伪造XFF头的时候,就可以用client-ip代替,直接指明伪造ip2)
X-Forwarded-For:简称XFF头,它代表客户端,也就是HTTP的请求端真实的IP,只有在通过了HTTP 代理或者负载均衡服务器时才会添加该项。xff是http的拓展头部,作用是使Web服务器获取访问用户的IP真实地址(可伪造)。由于很多用户通过代理服务器进行访问,服务器只能获取代理服务器的IP地址,而xff的作用在于记录用户的真实IP,以及代理服务器的IP。格式为:X-Forwarded-For: 本机IP, 代理1IP, 代理2IP, 代理2IP
请求头、响应头全部内容
HTTP请求头
Accept:浏览器可接受的MIME类型。
Accept-Charset:浏览器可接受的字符集。
Accept-Encoding:浏览器能够进行解码的数据编码方式,比如gzip。Servlet能够向支持gzip的浏览器返回经gzip编码的HTML页面。许多情形下这可以减少5到10倍的下载时间。
Accept-Language:浏览器所希望的语言种类,当服务器能够提供一种以上的语言版本时要用到。
Authorization:授权信息,通常出现在对服务器发送的WWW-Authenticate头的应答中。Connection:表示是否需要持久连接。如果Servlet看到这里的值为“Keep-Alive”,或者看到请求使用的是HTTP 1.1(HTTP 1.1默认进行持久连接),它就可以利用持久连接的优点,当页面包含多个元素时(例如Applet,图片),显著地减少下载所需要的时间。要实现这一点,Servlet需要在应答中发送一个Content-Length头,最简单的实现方法是:先把内容写入ByteArrayOutputStream,然后在正式写出内容之前计算它的大小。
Content-Length:表示请求消息正文的长度。
Cookie:这是最重要的请求头信息之一From:请求发送者的email地址,由一些特殊的Web客户程序使用,浏览器不会用到它。
Host:初始URL中的主机和端口。If-Modified-Since:只有当所请求的内容在指定的日期之后又经过修改才返回它,否则返回304“Not Modified”应答。
Pragma:指定“no-cache”值表示服务器必须返回一个刷新后的文档,即使它是代理服务器而且已经有了页面的本地拷贝。
Referer:包含一个URL,用户从该URL代表的页面出发访问当前请求的页面。
User-Agent:浏览器类型,如果Servlet返回的内容与浏览器类型有关则该值非常有用。UA-Pixels,UA-Color,UA-OS,UA-CPU:由某些版本的IE浏览器所发送的非标准的请求头,表示屏幕大小、颜色深度、操作系统和CPU类型。
HTTP应答头
Web服务器的HTTP应答一般由以下几项构成:一个状态行,一个或多个应答头,一个空行,内容文档。设置HTTP应答头往往和设置状态行中的状态代码结合起来。例如,有好几个表示“文档位置已经改变”的状态代码都伴随着一个Location头,而401(Unauthorized)状态代码则必须伴随一个WWW-Authenticate头。
然而,即使在没有设置特殊含义的状态代码时,指定应答头也是很有用的。应答头可以用来完成:设置Cookie,指定修改日期,指示浏览器按照指定的间隔刷新页面,声明文档的长度以便利用持久HTTP连接,等等许多其他任务。
设置应答头最常用的方法是HttpServletResponse的setHeader,该方法有两个参数,分别表示应答头的名字和值。和设置状态代码相似,设置应答头应该在发送任何文档内容之前进行。
setContentType:设置Content-Type头。大多数Servlet都要用到这个方法。setContentLength:设置Content-Length头。对于支持持久HTTP连接的浏览器来说,这个函数是很有用的。
addCookie:设置一个Cookie(ServletAPI中没有setCookie方法,因为应答往往包含多个Set-Cookie头)。
另外,如上节介绍,sendRedirect方法设置状态代码302时也会设置Location头。HTTP应答头 说明
Allow 服务器支持哪些请求方法(如GET、POST等)。Content-Encoding 文档的编码(Encode)方法。只有在解码之后才可以得到Content-Type头指定的内容类型。利用
gzip压缩文档能够显著地减少HTML文档的下载时间。Java的GZIPOutputStream可以很方便地进行gzip压缩,但只有Unix上的Netscape和Windows上的IE 4、IE 5才支持它。因此,Servlet应该通过查看Accept-Encoding头(即request.getHeader(“Accept-Encoding”))检查浏览器是否支持gzip,为支持gzip的浏览器返回经gzip压缩的HTML页面,为其他浏览器返回普通页面。Content-Length 表示内容长度。只有当浏览器使用持久HTTP连接时才需要这个数据。如果你想要利用持久连接的优势,可以把输出文档写入ByteArrayOutputStram,完成后查看其大小,然后把该值放入Content-Length头,最后通过byteArrayStream.writeTo(response.getOutputStream()发送内容。
Content-Type 表示后面的文档属于什么MIME类型。Servlet默认为text/plain,但通常需要显式地指定为
text/html。由于经常要设置Content-Type,因此HttpServletResponse提供了一个专用的方法setContentType。Date 当前的GMT时间。你可以用setDateHeader来设置这个头以避免转换时间格式的麻烦。
Expires 应该在什么时候认为文档已经过期,从而不再缓存它?
Last-Modified 文档的最后改动时间。客户可以通过If-Modified-Since请求头提供一个日期,该请求将被视为一个条件GET,只有改动时间迟于指定时间的文档才会返回,否则返回一个304(Not Modified)状态。Last-Modified也可用setDateHeader方法来设置。Location 表示客户应当到哪里去提取文档。Location通常不是直接设置的,而是通过HttpServletResponse的sendRedirect方法,该方法同时设置状态代码为302。
Refresh 表示浏览器应该在多少时间之后刷新文档,以秒计。除了刷新当前文档之外,你还可以通过
让浏览器读取指定的页面。注意这种功能通常是通过设置HTML页面HEAD区的
[注,笔者开始把这段代码复制到该博客时,发现一直在向host/path,跳转,最后查看网络,才发现这里这段代码发挥了作用,并没有当作简单的文本]实现,这是因为,自动刷新或重定向对于那些不能使用
CGI或Servlet的HTML编写者十分重要。但是,对于Servlet来说,直接设置Refresh头更加方便。注意Refresh的意义是“N秒之后刷新本页面或访问指定页面”,而不是“每隔N秒刷新本页面或访问指定页面”。因此,连续刷新要求每次都发送一个Refresh头,而发送204状态代码则可以阻止浏览器继续刷新,不管是使用Refresh头还是<META HTTP-EQUIV=”Refresh” …>。注意Refresh头不属于HTTP 1.1正式规范的一部分,而是一个扩展,但Netscape和IE都支持它。Server 服务器名字。Servlet一般不设置这个值,而是由Web服务器自己设置。
Set-Cookie设置和页面关联的Cookie。Servlet不应使用response.setHeader(“Set-Cookie”, …),而是应使用HttpServletResponse提供的专用方法addCookie。参见下文有关Cookie设置的讨论。WWW-Authenticate 客户应该在Authorization头中提供什么类型的授权信息?在包含401(Unauthorized)状态行的应答中这个头是必需的。例如,
response.setHeader(“WWW-Authenticate”, “BASIC realm="executives"“)。注意Servlet一般不进行这方面的处理,而是让Web服务器的专门机制来控制受密码保护页面的访问(例如.htaccess)。
响应码
HTTP状态码的常见类别和含义如下:
- 1xx(信息性状态码):表示请求已被接受,需要继续处理。
- 2xx(成功状态码):表示请求已成功被服务器接收、理解、并接受处理。
- 3xx(重定向状态码):表示需要客户端采取进一步的操作才能完成请求。
- 4xx(客户端错误状态码):表示客户端请求错误或无法完成请求。
- 5xx(服务器错误状态码):表示服务器在处理请求时发生错误。
常见的HTTP状态码包括:
- 200 OK:请求成功。
- 302 Found:请求的资源已被临时移动到新的位置。
- 400 Bad Request:请求无效或不完整。
- 401 Unauthorized:未授权,需要身份验证。
- 403 Forbidden:服务器拒绝请求。
- 404 Not Found:请求的资源不存在。
- 500 Internal Server Error:服务器内部错误。
- 503 Service Unavailable:服务器暂时无法处理请求。
session利用的小思路
常见的基本就两种,session文件包含和session反序列化
原文链接:https://xz.aliyun.com/t/10662
同源策略
1 | 作者:laixiangran |
含义
1995年,同源政策由 Netscape 公司引入浏览器。目前,所有浏览器都实行这个政策。
最初,它的含义是指,A网页设置的 Cookie,B网页不能打开,除非这两个网页”同源”。所谓”同源”指的是”三个相同”。
- 协议相同
- 域名相同
- 端口相同
举例来说,http://www.example.com/dir/page.html这个网址,协议是http://,域名是www.example.com,端口是80(默认端口可以省略)。
它的同源情况如下
http://www.example.com/dir2/other.html:同源http://example.com/dir/other.html:不同源(域名不同)http://v2.www.example.com/dir/other.html:不同源(域名不同)http://www.example.com:81/dir/other.html:不同源(端口不同)
限制范围
随着互联网的发展,”同源政策”越来越严格。目前,如果非同源,共有三种行为受到限制。
(1) Cookie、LocalStorage 和 IndexDB 无法读取。
(2) DOM 无法获得。
(3) AJAX 请求不能发送。
虽然这些限制是必要的,但是有时很不方便,合理的用途也受到影响。下面,我将详细介绍,如何规避上面三种限制。
为什么要有跨域限制
因为存在浏览器同源策略,所以才会有跨域问题。那么浏览器是出于何种原因会有跨域的限制呢。其实不难想到,跨域限制主要的目的就是为了用户的上网安全。
如果浏览器没有同源策略,会存在什么样的安全问题呢。下面从 DOM 同源策略和 XMLHttpRequest 同源策略来举例说明:
如果没有 DOM 同源策略,也就是说不同域的 iframe 之间可以相互访问,那么黑客可以这样进行攻击:
- 做一个假网站,里面用 iframe 嵌套一个银行网站
http://mybank.com。- 把 iframe 宽高啥的调整到页面全部,这样用户进来除了域名,别的部分和银行的网站没有任何差别。
- 这时如果用户输入账号密码,我们的主网站可以跨域访问到
http://mybank.com的 dom 节点,就可以拿到用户的账户密码了。
如果没有 XMLHttpRequest 同源策略,那么黑客可以进行 CSRF(跨站请求伪造) 攻击:
- 用户登录了自己的银行页面
http://mybank.com,http://mybank.com向用户的 cookie 中添加用户标识。- 用户浏览了恶意页面
http://evil.com,执行了页面中的恶意 AJAX 请求代码。http://evil.com向http://mybank.com发起 AJAX HTTP 请求,请求会默认把http://mybank.com对应 cookie 也同时发送过去。- 银行页面从发送的 cookie 中提取用户标识,验证用户无误,response 中返回请求数据。此时数据就泄露了。
- 而且由于 Ajax 在后台执行,用户无法感知这一过程。
因此,有了浏览器同源策略,我们才能更安全的上网。
跨域的解决方法
从上面我们了解到了浏览器同源策略的作用,也正是有了跨域限制,才使我们能安全的上网。但是在实际中,有时候我们需要突破这样的限制,因此下面将介绍几种跨域的解决方法。
CORS(跨域资源共享)
CORS(Cross-origin resource sharing,跨域资源共享)是一个 W3C 标准,定义了在必须访问跨域资源时,浏览器与服务器应该如何沟通。CORS 背后的基本思想,就是使用自定义的 HTTP 头部让浏览器与服务器进行沟通,从而决定请求或响应是应该成功,还是应该失败。
CORS 需要浏览器和服务器同时支持。目前,所有浏览器都支持该功能,IE 浏览器不能低于 IE10。
整个 CORS 通信过程,都是浏览器自动完成,不需要用户参与。对于开发者来说,CORS 通信与同源的 AJAX 通信没有差别,代码完全一样。浏览器一旦发现 AJAX 请求跨源,就会自动添加一些附加的头信息,有时还会多出一次附加的请求,但用户不会有感觉。
因此,实现 CORS 通信的关键是服务器。只要服务器实现了 CORS 接口,就可以跨源通信。
浏览器将CORS请求分成两类:
简单请求(simple request)和非简单请求(not-so-simple request)。
只要同时满足以下两大条件,就属于简单请求。
1.请求方法是以下三种方法之一:
- HEAD
- GET
- POST
2.HTTP的头信息不超出以下几种字段:
- Accept
- Accept-Language
- Content-Language
- Last-Event-ID
- Content-Type:只限于三个值 application/x-www-form-urlencoded、multipart/form-data、text/plain
凡是不同时满足上面两个条件,就属于非简单请求。
浏览器对这两种请求的处理,是不一样的。
简单请求
- 在请求中需要附加一个额外的 Origin 头部,其中包含请求页面的源信息(协议、域名和端口),以便服务器根据这个头部信息来决定是否给予响应。例如:
Origin: http://www.laixiangran.cn- 如果服务器认为这个请求可以接受,就在 Access-Control-Allow-Origin 头部中回发相同的源信息(如果是公共资源,可以回发 * )。例如:
Access-Control-Allow-Origin:http://www.laixiangran.cn- 没有这个头部或者有这个头部但源信息不匹配,浏览器就会驳回请求。正常情况下,浏览器会处理请求。注意,请求和响应都不包含 cookie 信息。
- 如果需要包含 cookie 信息,ajax 请求需要设置 xhr 的属性 withCredentials 为 true,服务器需要设置响应头部
Access-Control-Allow-Credentials: true。
非简单请求
浏览器在发送真正的请求之前,会先发送一个 Preflight 请求给服务器,这种请求使用 OPTIONS 方法,发送下列头部:
- Origin:与简单的请求相同。
- Access-Control-Request-Method: 请求自身使用的方法。
- Access-Control-Request-Headers: (可选)自定义的头部信息,多个头部以逗号分隔。
例如:
1 | Origin: http://www.laixiangran.cn |
发送这个请求后,服务器可以决定是否允许这种类型的请求。服务器通过在响应中发送如下头部与浏览器进行沟通:
- Access-Control-Allow-Origin:与简单的请求相同。
- Access-Control-Allow-Methods: 允许的方法,多个方法以逗号分隔。
- Access-Control-Allow-Headers: 允许的头部,多个方法以逗号分隔。
- Access-Control-Max-Age: 应该将这个 Preflight 请求缓存多长时间(以秒表示)。
例如:
Access-Control-Allow-Origin: http://www.laixiangran.cn
Access-Control-Allow-Methods: GET, POST
Access-Control-Allow-Headers: NCZ
Access-Control-Max-Age: 1728000
一旦服务器通过 Preflight 请求允许该请求之后,以后每次浏览器正常的 CORS 请求,就都跟简单请求一样了。
优点
- CORS 通信与同源的 AJAX 通信没有差别,代码完全一样,容易维护。
- 支持所有类型的 HTTP 请求。
缺点
- 存在兼容性问题,特别是 IE10 以下的浏览器。
- 第一次发送非简单请求时会多一次请求。
JSONP 跨域
由于
script标签不受浏览器同源策略的影响,允许跨域引用资源。因此可以通过动态创建 script 标签,然后利用 src 属性进行跨域,这也就是 JSONP 跨域的基本原理。
直接通过下面的例子来说明 JSONP 实现跨域的流程:
1 | // 1. 定义一个 回调函数 handleResponse 用来接收返回的数据 |
优点
- 使用简便,没有兼容性问题,目前最流行的一种跨域方法。
缺点
- 只支持 GET 请求。
- 由于是从其它域中加载代码执行,因此如果其他域不安全,很可能会在响应中夹带一些恶意代码。
- 要确定 JSONP 请求是否失败并不容易。虽然 HTML5 给 script 标签新增了一个 onerror 事件处理程序,但是存在兼容性问题。
图像 Ping 跨域
由于
img标签不受浏览器同源策略的影响,允许跨域引用资源。因此可以通过 img 标签的 src 属性进行跨域,这也就是图像 Ping 跨域的基本原理。
直接通过下面的例子来说明图像 Ping 实现跨域的流程:
1 | var img = new Image(); |
优点
- 用于实现跟踪用户点击页面或动态广告曝光次数有较大的优势。
缺点
- 只支持 GET 请求。
- 只能浏览器与服务器的单向通信,因为浏览器不能访问服务器的响应文本。
服务器代理
浏览器有跨域限制,但是服务器不存在跨域问题,所以可以由服务器请求所有域的资源再返回给客户端。
**服务器代理是万能的**。
document.domain 跨域
对于主域名相同,而子域名不同的情况,可以使用 document.domain 来跨域。这种方式非常适用于 iframe 跨域的情况。
比如,
有一个页面,它的地址是 http://www.laixiangran.cn/a.html,在这个页面里面有一个 iframe,它的 src 是 http://laixiangran.cn/b.html。
很显然,这个页面与它里面的 iframe 框架是不同域的,所以我们是无法通过在页面中书写 js 代码来获取 iframe 中的东西的。
这个时候,document.domain 就可以派上用场了,我们只要把
http://www.laixiangran.cn/a.html和http://laixiangran.cn/b.html这两个页面的 document.domain 都设成相同的域名就可以了。但要注意的是,document.domain 的设置是有限制的,我们只能把 document.domain 设置成自身或更高一级的父域,且主域必须相同。例如:a.b.laixiangran.cn中某个文档的 document.domain 可以设成a.b.laixiangran.cn、b.laixiangran.cn、laixiangran.cn中的任意一个,但是不可以设成c.a.b.laixiangran.cn,因为这是当前域的子域,也不可以设成baidu.com,因为主域已经不相同了。
例如,在页面 http://www.laixiangran.cn/a.html 中设置document.domain:
1 | <iframe src="http://laixiangran.cn/b.html" id="myIframe" onload="test()"> |
在页面 http://laixiangran.cn/b.html 中也设置 document.domain,而且这也是必须的,虽然这个文档的 domain 就是 laixiangran.cn,但是还是必须显式地设置 document.domain 的值:
1 | <script> |
这样,http://www.laixiangran.cn/a.html 就可以通过 js 访问到 http://laixiangran.cn/b.html 中的各种属性和对象了。
window.name 跨域
window 对象有个 name 属性,该属性有个特征:即在一个窗口(window)的生命周期内,窗口载入的所有的页面(不管是相同域的页面还是不同域的页面)都是共享一个
window.name的,每个页面对window.name都有读写的权限,window.name是持久存在一个窗口载入过的所有页面中的,并不会因新页面的载入而进行重置。
通过下面的例子介绍如何通过 window.name 来跨域获取数据的。
页面 http://www.laixiangran.cn/a.html 的代码:
1 | <iframe src="http://laixiangran.cn/b.html" id="myIframe" onload="test()" style="display: none;"> |
页面 http://laixiangran.cn/b.html 的代码:
1 | <script type="text/javascript"> |
location.hash 跨域
location.hash 方式跨域,是子框架修改父框架 src 的 hash 值,通过这个属性进行传递数据,且更改 hash 值,页面不会刷新。但是传递的数据的字节数是有限的。
页面 http://www.laixiangran.cn/a.html 的代码:
1 | <iframe src="http://laixiangran.cn/b.html" id="myIframe" onload="test()" style="display: none;"> |
页面 http://laixiangran.cn/b.html 的代码:
1 | <script type="text/javascript"> |
postMessage 跨域
window.postMessage(message,targetOrigin) 方法是 HTML5 新引进的特性,可以使用它来向其它的 window 对象发送消息,无论这个 window 对象是属于同源或不同源。这个应该就是以后解决 dom 跨域通用方法了。
调用 postMessage 方法的 window 对象是指要接收消息的那一个 window 对象,该方法的第一个参数 message 为要发送的消息,类型只能为字符串;第二个参数 targetOrigin 用来限定接收消息的那个 window 对象所在的域,如果不想限定域,可以使用通配符 *。
需要接收消息的 window 对象,可是通过监听自身的 message 事件来获取传过来的消息,消息内容储存在该事件对象的 data 属性中。
页面 http://www.laixiangran.cn/a.html 的代码:
1 | <iframe src="http://laixiangran.cn/b.html" id="myIframe" onload="test()" style="display: none;"> |
页面 http://laixiangran.cn/b.html 的代码:
1 | <script type="text/javascript"> |
参考资料
记一次docker搭建复现web题目环境
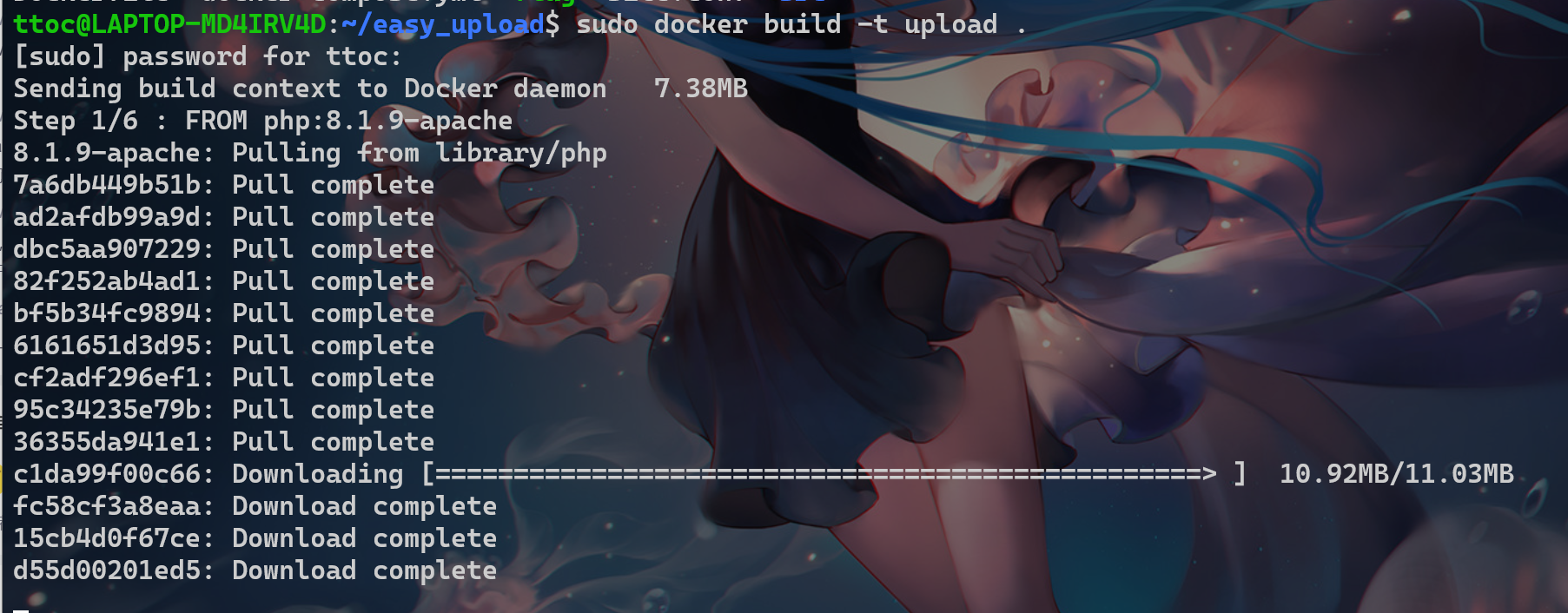
1.构造镜像

可以看到这里有个Dockerfile文件
docker build -t image_name .
//这里是利用dockerfile创建一个命名为image_name的镜像【后面的点不能少】
2.查看镜像是否创建成功
docker images

3.运行启动镜像,创建环境
docker run -i -d -P image_name

4.查看容器启动端口
docker ps -a

可以看到是再32768端口运行
访问
127.0.0.1:32768
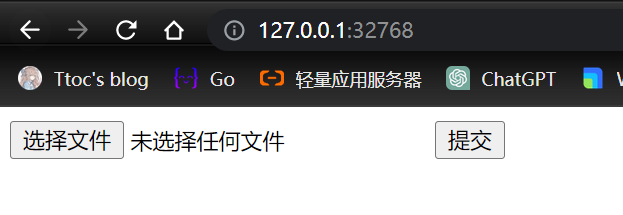
搭建成功
5.关闭容器
docker ps -a

docker stop CONTAINER ID

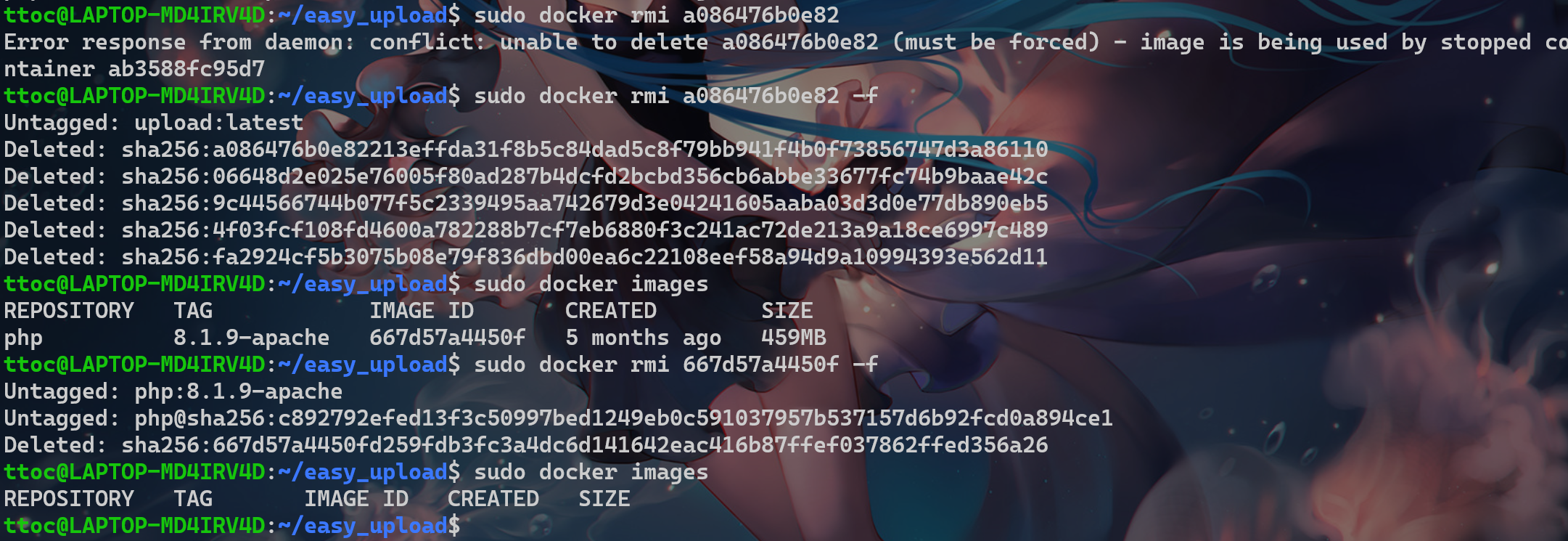
6.删除镜像【觉得环境镜像后面有用的可以留着】
docker images

docker rmi IMAGE ID//注:有的需要强制,所以需要在后面加上参数
-f
ps.进入容器环境
sudo docker exec -it filechecker_pro_max_web1_1 /bin/bash
#filechecker_pro_max_web1_1为容器名字

反向代理和正向代理的区别
正向代理和反向代理都是代理服务器的应用,它们的主要区别在于代理服务器的位置和作用:
正向代理(Forward Proxy):代理服务器位于
客户端和目标服务器之间,代理服务器充当客户端的代表,向目标服务器发送请求并将响应返回给客户端。客户端向代理服务器发出请求,然后代理服务器将请求转发给目标服务器,最终将响应返回给客户端。正向代理主要用于访问外部网络或突破访问限制,客户端需要知道代理服务器的存在并向其发出请求。反向代理(Reverse Proxy):代理服务器位于
目标服务器和客户端之间,代理服务器充当目标服务器的代表,向目标服务器接收请求并将响应返回给客户端。客户端向代理服务器发出请求,代理服务器根据一定规则将请求转发到目标服务器上,并将目标服务器的响应返回给客户端。反向代理主要用于负载均衡、安全控制和缓存等方面,客户端不需要知道目标服务器的存在。
总的来说,正向代理和反向代理都是代理服务器的应用,它们的主要区别在于代理服务器的位置和作用。
正向代理是客户端向代理服务器发出请求,代理服务器再向目标服务器发送请求,并将响应返回给客户端;
反向代理是客户端向代理服务器发出请求,代理服务器再将请求转发到目标服务器上,并将目标服务器的响应返回给客户端。
以nginx为例,访问静态文件与php文件区别是什么?如何配置php文件的解析?
在Nginx中,访问静态文件和PHP文件的处理方式有所不同。静态文件通常是指图片、CSS、JavaScript等不需要动态生成的文件,而PHP文件则是需要动态生成HTML内容的文件。
对于静态文件的访问,Nginx可以直接返回这些文件,不需要对其进行任何处理,这可以提高Nginx的响应速度和性能。配置Nginx处理静态文件的方式通常如下:
1 | location /static { |
上面的配置表示,当访问/example.com/static时,Nginx会将请求映射到/var/www/example.com/static目录下,并返回该目录下的index.html文件(如果存在)。
对于
PHP文件的访问,Nginx需要将请求发送给PHP解释器进行处理,并将解析后的结果返回给客户端。为了实现这一功能,需要配置Nginx与PHP解释器之间的通信方式。通常,可以使用FastCGI协议来实现Nginx与PHP解释器之间的通信,具体配置方式如下:
1 | location / { |
上面的配置表示,当访问/example.com时,Nginx会首先查找该目录下是否存在请求的文件,如果存在则直接返回该文件,否则将请求转发到FastCGI服务,FastCGI服务会将请求发送给PHP解释器进行处理。其中,location ~ .php$ 表示匹配所有以.php结尾的请求,fastcgi_pass指定了PHP解释器的地址,SCRIPT_FILENAME指定了PHP解释器需要处理的文件路径。需要注意的是,需要安装PHP解释器和FastCGI服务,具体安装方式可以参考官方文档或其他资源。
IIOP的NAT网络问题
IIOP(Internet Inter-ORB Protocol)是一种用于不同计算机之间通信的协议,常用于分布式应用程序中。然而,在使用IIOP时,如果涉及到NAT(网络地址转换)网络,则可能会遇到一些问题。
NAT是一种将私有IP地址转换为公共IP地址的技术,以实现在不同网络之间通信。但是,由于NAT会修改数据包的源地址和目标地址,因此可能会影响到IIOP通信的正确性和可靠性,
具体表现为:
- IIOP
请求无法到达目标机器:由于NAT会改变数据包的源IP地址,因此,当一个IIOP请求离开私有网络时,NAT会将源IP地址修改为公共IP地址。但是,由于IIOP协议中包含了源IP地址,因此,当响应返回时,如果源IP地址不是私有IP地址,则响应将无法到达目标机器,导致通信失败。- IIOP
响应无法到达源机器:类似地,当一个IIOP请求到达目标机器时,NAT会将目标IP地址修改为私有IP地址,以便将响应返回到源机器。但是,由于IIOP协议中包含了目标IP地址,因此,如果响应返回的目标IP地址不是公共IP地址,则响应无法到达源机器,导致通信失败。- IIOP
会话终止:如果一个IIOP会话的任一方在使用NAT网络时发生地址转换,那么会话可能会在NAT设备上终止,导致通信中断。为了解决这些问题,可以使用一些技术,例如
端口映射、反向代理等,以确保IIOP请求和响应正确到达目标机器和源机器。
那么可以根据网站编写的语言,用对应的语言对iiop的规则进行重写,以达到减少通讯冲突的结果
以java和go对iiop的规则进行重写为例
Java可以使用一些技术来重写IIOP规则,以确保IIOP在NAT网络中的正确性和可靠性。具体来说,以下是几种Java技术:
- 使用Java Naming and Directory Interface (JNDI):
JNDI是Java中用于访问命名和目录服务的API。可以使用JNDI来连接到IIOP服务器,并通过命名服务的名称解析来避免在IIOP请求和响应中使用IP地址。这样可以减少NAT对IIOP请求和响应的影响。- 使用Java IIOP ORB属性:Java IIOP ORB属性是一组用于配置IIOP ORB的属性,
包括IP地址和端口等。可以在代码中设置这些属性,以确保IIOP请求和响应正确到达目标机器和源机器。- 使用Java IIOP反向代理:
Java IIOP反向代理是一种用于在公共网络上部署的IIOP服务器。反向代理可以将IIOP请求转发到私有网络中的IIOP服务器,以避免在IIOP请求和响应中使用IP地址。Java IIOP反向代理通常是基于Java IIOP ORB实现的。
Go语言可以使用一些技术来重写IIOP规则,以确保IIOP在NAT网络中的正确性和可靠性。以下是几种Go技术:
- 使用Go CORBA库:
Go CORBA库是一组用于CORBA开发的Go语言库。可以使用Go CORBA库连接到IIOP服务器,并通过CORBA对象的名称解析来避免在IIOP请求和响应中使用IP地址。这样可以减少NAT对IIOP请求和响应的影响。- 使用Go IIOP反向代理:Go IIOP反向代理是一种用于在公共网络上部署的IIOP服务器。
反向代理可以将IIOP请求转发到私有网络中的IIOP服务器,以避免在IIOP请求和响应中使用IP地址。Go IIOP反向代理通常是基于Go CORBA库实现的。- 使用Go TCP代理:Go TCP代理是一种用于在公共网络上部署的TCP服务器。可以将
IIOP请求和响应通过TCP代理传输,并在代理服务器上进行地址转换,以确保IIOP请求和响应正确到达目标机器和源机器。
可以以实际的情况用不同语言和方法进行修改以达到iiop与net冲突减少或者消失的目的