1、MD5——示例
21232F297A57A5A743894A0E4A801FC3
一般MD5值是32位由数字0-9和字母a-f所组成的字符串,如图。如果出现这个范围以外的字符说明这可能是个错误的md5值,就没必要再拿去解密了。16位值是取的是8~24位。

md5的三个特征:
1.确定性:一个原始数据的MD5值是唯一的,同一个原始数据不可能会计算出多个不同的MD5值。
2.碰撞性:原始数据与其MD5值并不是一一对应的,有可能多个原始数据计算出来的MD5值是一样的,这就是碰撞。
3.不可逆:也就是说如果告诉你一个MD5值,你是无法通过它还原出它的原始数据的,这不是你的技术不够牛,这是由它的算法所决定的。因为根据第2点,一个给定的MD5值是可能对应多个原始数据的,并且理论上讲是可以对应无限多个原始数据,所有无法确定到底是由哪个原始数据产生的。
2、sha1——示例
d033e22ae348aeb5660fc2140aec35850c4da997
这种加密的密文特征跟MD5差不多,只不过位数是40
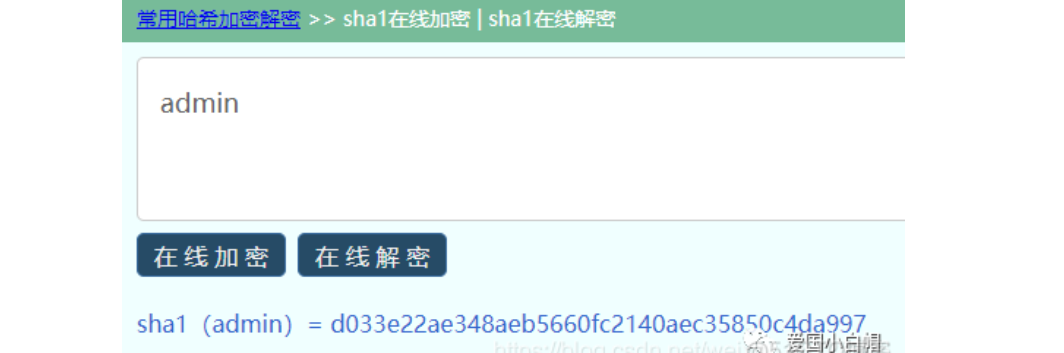
3、HMAC算法——示例
5b696ae7da9442ead7adc24d03cedb65
HMAC (Hash-based Message Authentication Code) 常用于接口签名验证,这种算法就是在前两种加密的基础上引入了秘钥,而秘钥又只有传输双方才知道,所以基本上是破解不了的
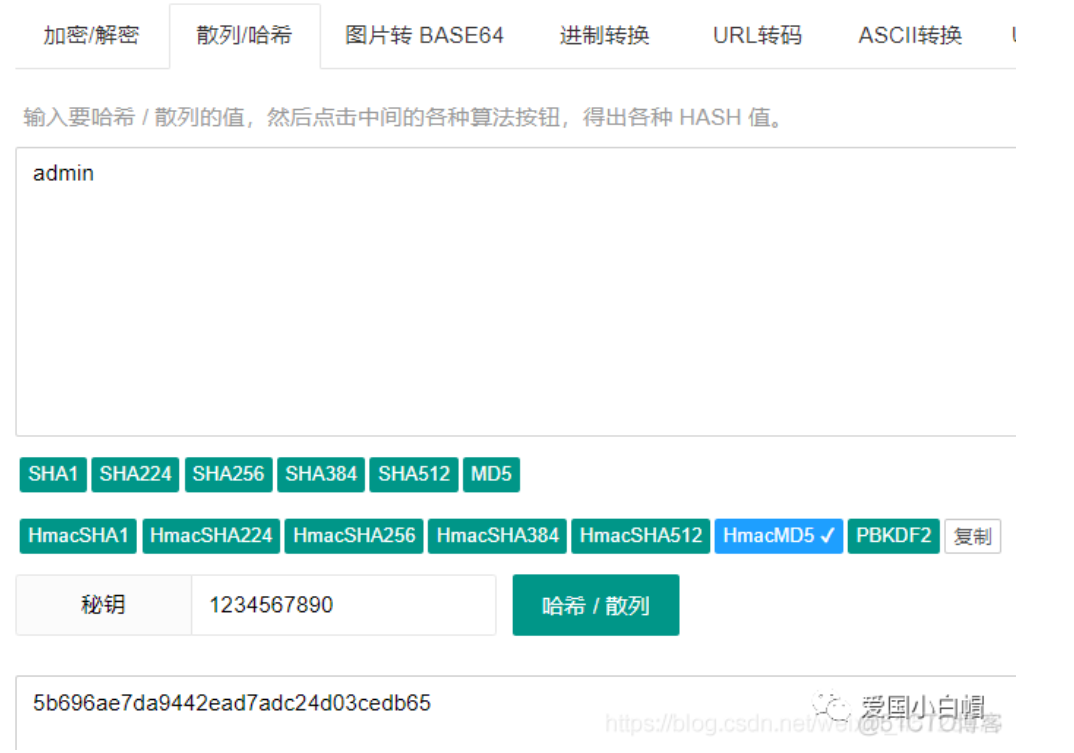
4、NTLM——示例
209c6174da490caeb422f3fa5a7ae634
这种加密是Windows的哈希密码,是 Windows NT 早期版本的标准安全协议。与它相同的还有Domain Cached Credentials(域哈希)。
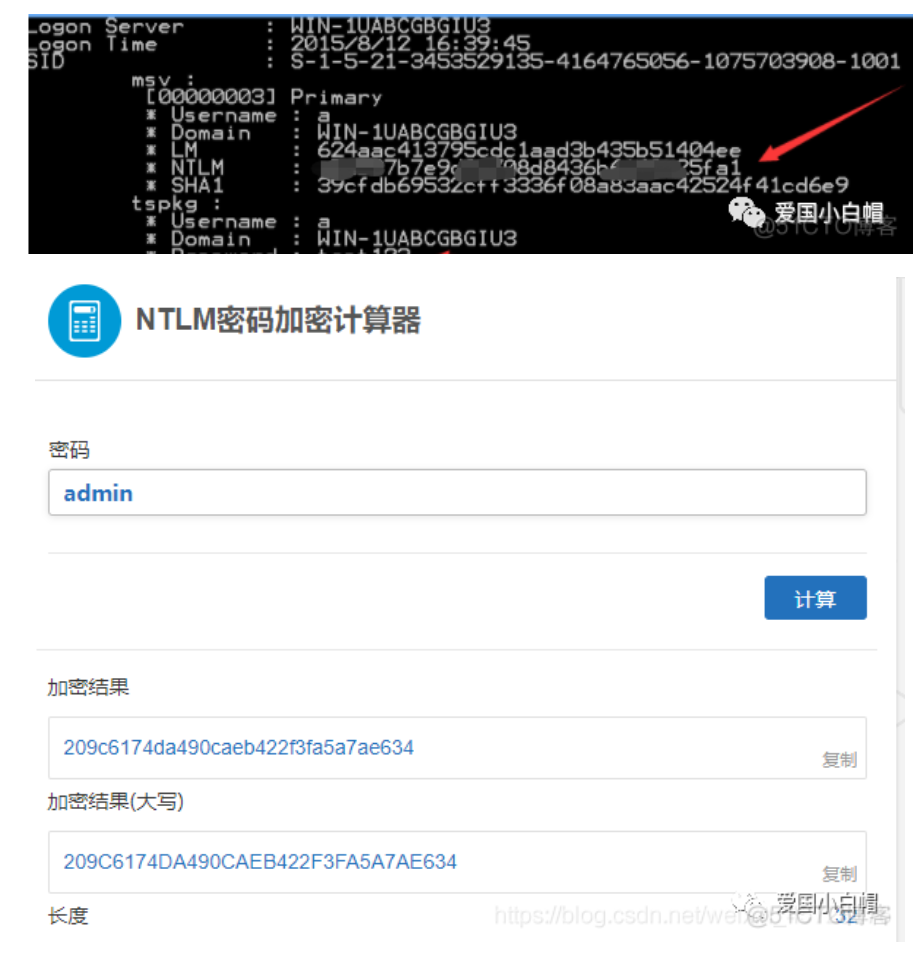
相似加密类型
1 |
|
常用解密网站:
www.cmd5.com(带批量解密工具)
www.somd5.com
cmd5.la
pmd5.com
www.ttmd5.com(带批量解密工具)
Base64、Base58、Base32、Base16、Base85、Base100等相似加密类型
1、Base64——示例
YWRtaW4tcm9vdA==
一般情况下密文尾部都会有两个等号,明文很少的时候则没有
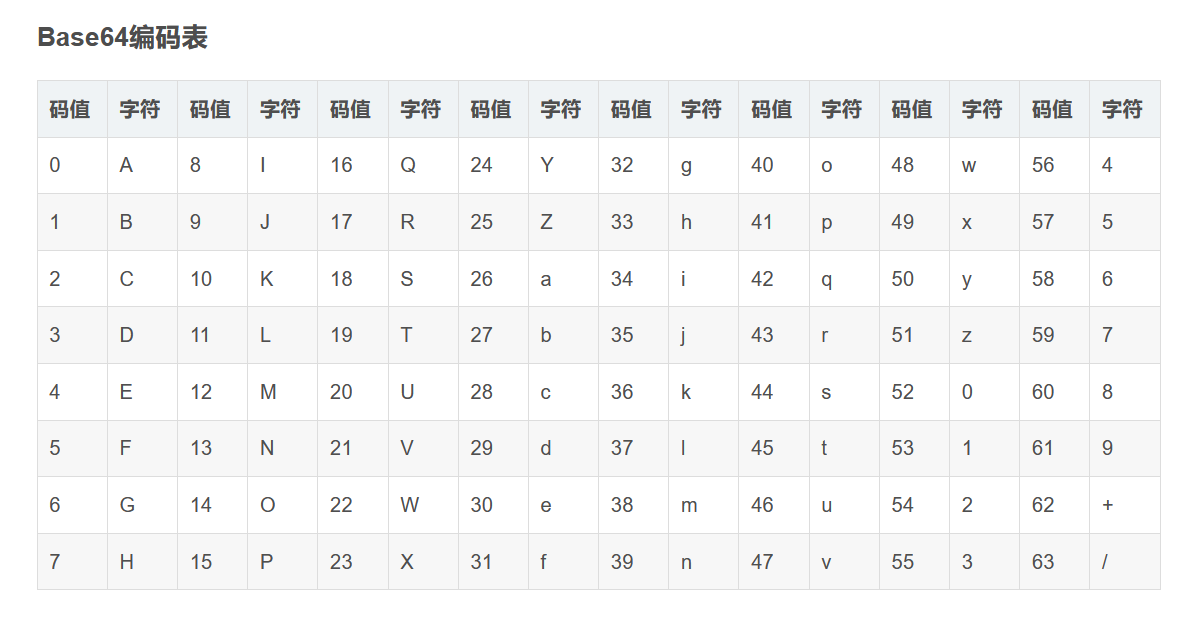
Base64编码要求把3个8位字节(38=24)转化为4个6位的字节(46=24),之后在6位的前面补两个0,形成8位一个字节的形式。如果剩下的字符不足3个字节,则用0填充,输出字符使用‘=’,因此编码后输出的文本末尾可能会出现1或2个‘=’,如图。

为了保证所输出的编码位可读字符,Base64制定了一个编码表,以便进行统一转换。编码表的大小为2^6=64,这也是Base64名称的由来。
Base64使用注意问题
一、Base64和URL传参问题
标准的Base64并不适合直接放在URL里传输,因为URL编码器会把标准Base64中的“/”和“+”字符变为形如“%XX”的形式,而这些“%”号在存入数据库时还需要再进行转换,因为ANSI SQL中已将“%”号用作通配符。
为解决此问题,可采用一种用于URL的改进Base64编码,它在末尾填充’=’号,并将标准Base64中的“+”和“/”分别改成了“-”和“_”,这样就免去了在URL编解码和数据库存储时所要作的转换,避免了编码信息长度在此过程中的增加,并统一了数据库、表单等处对象标识符的格式。
二、Base64和URL传参问题改善
另有一种用于正则表达式的改进Base64变种,它将“+”和“/”改成了“!”和“-”,因为“+”,“*”以及前面在IRCu中用到的“[”和“]”在正则表达式中都可能具有特殊含义。
此外还有一些变种,它们将“+/”改为“-”或“.”(用作编程语言中的标识符名称)或“.-”(用于XML中的Nmtoken)甚至“_:”(用于XML中的Name)。
三、Base64转换后比原有的字符串长1/3
Base64要求把每三个8Bit的字节转换为四个6Bit的字节(38 = 46 = 24),然后把6Bit再添两位高位0,组成四个8Bit的字节,也就是说,转换后的字符串理论上将要比原来的长1/3。
四、Base64转换总结
Base64转换,最好是不要用在加密上,尤其是参数加密,很容易出问题。
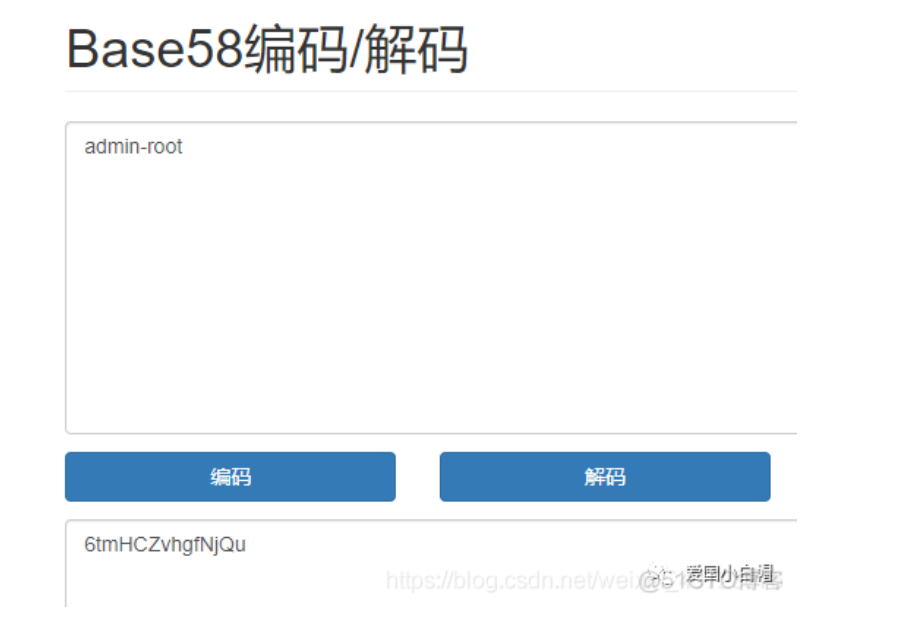
2、Base58——示例
6tmHCZvhgfNjQu
它最大的特点是没有等号
Base58是用于比特币(Bitcoin)中使用的一种独特的编码方式,主要用于产生Bitcoin的钱包地址。
相比Base64,Base58不使用数字”0”,字母大写”O”,字母大写”I”,和字母小写”l”,以及”+“和”/“符号。
比特币的Base58字母表:
123456789ABCDEFGHJKLMNPQRSTUVWXYZabcdefghijkmnopqrstuvwxyz
简单的说:Base58一种编码方式,跟十进制,十六进制一样,不过更短更省空间。
Base58的原理是什么?
二进制:0和1
十进制:1到10
十六进制:十进制的基础上加上了A-F 六个字母
Base58可以理解为一种58进制。
Base58包含了阿拉伯数字、小写英文字母,大写英文字母。
但是去掉了一些容易混淆的数字和字母:0(数字0)、O(o的大写字母)、l( L的小写字母)、I(i的大写字母)
3、Base32——示例
GEZDGNBVGY3TQOJQGE======
他的特点是明文超过十个后面就会有很多等号
Base32使用了ASCII编码中可打印的32个字符(大写字母A-Z和数字2-7)对任意字节数据进行编码.Base32将串起来的二进制数据按照5个二进制位分为一组,由于传输数据的单位是字节(即8个二进制位).所以分割之前的二进制位数是40的倍数(40是5和8的最小公倍数).如果不足40位,则在编码后数据补充”=”,一个”=”相当于一个组(5个二进制位),编码后的数据是原先的8/5倍.
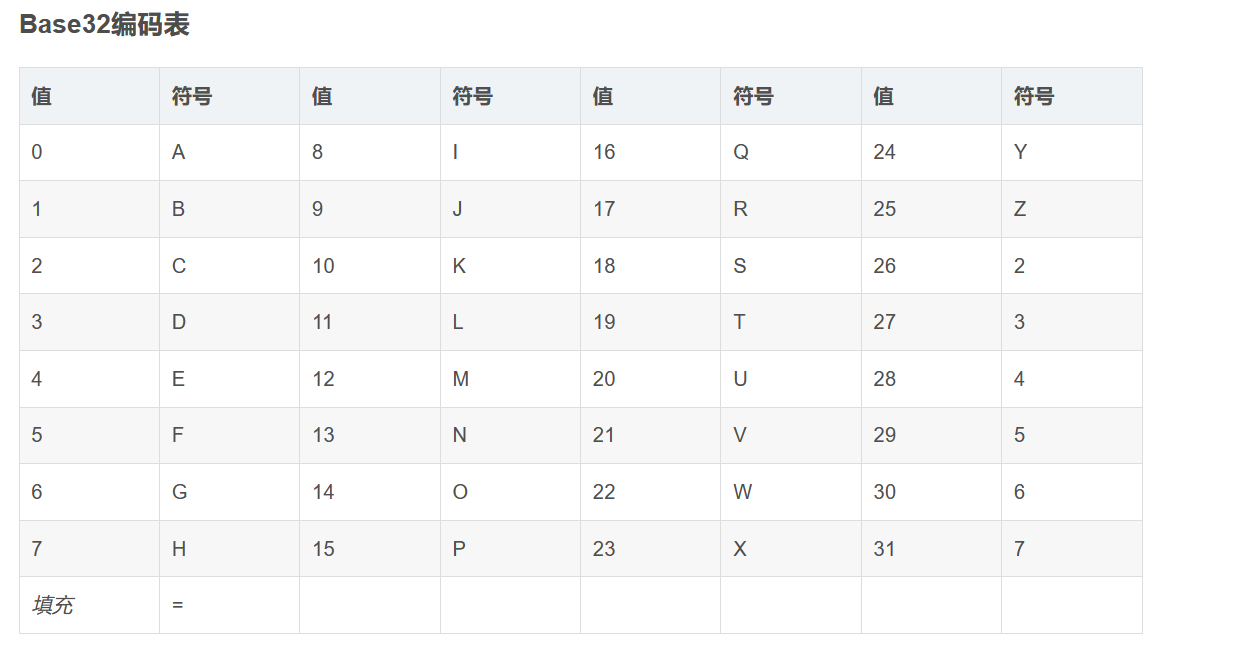
Base32将任意字符串按照字节进行切分,并将每个字节对应的二进制值(不足8比特高位补0)串联起来,按照5比特一组进行切分,并将每组二进制值转换成十进制来对应32个可打印字符中的一个。

由于数据的二进制传输是按照8比特一组进行(即一个字节),因此Base32按5比特切分的二进制数据必须是40比特的倍数(5和8的最小公倍数)。例如输入单字节字符“%”,它对应的二进制值是“100101”,前面补两个0变成“00100101”(二进制值不足8比特的都要在高位加0直到8比特),从左侧开始按照5比特切分成两组:“00100”和“101”,后一组不足5比特,则在末尾填充0直到5比特,变成“00100”和“10100”,这两组二进制数分别转换成十进制数,通过上述表格即可找到其对应的可打印字符“E”和“U”,但是这里只用到两组共10比特,还差30比特达到40比特,按照5比特一组还需6组,则在末尾填充6个“=”。填充“=”符号的作用是方便一些程序的标准化运行,大多数情况下不添加也无关紧要,而且,在URL中使用时必须去掉“=”符号。
与Base64相比,Base32具有许多优点:
1.适合不区分大小写的文件系统,更利于人类口语交流或记忆。
2.结果可以用作文件名,因为它不包含路径分隔符 “/”等符号。
3.排除了视觉上容易混淆的字符,因此可以准确的人工录入。(例如,RFC4648符号集忽略了数字“1”、“8”和“0”,因为它们可能与字母“I”,“B”和“O”混淆)。
4.排除填充符号“=”的结果可以包含在URL中,而不编码任何字符。
Base32也比Base16有优势:
·Base32比Base16占用的空间更小。(1000比特数据Base32需要200个字符,而Base16则为250个字符)
Base32的缺点:
·Base32比Base64多占用大约20%的空间。因为Base32使用8个ASCII字符去编码原数据中的5个字节数据,而Base64是使用4个ASCII字符去编码原数据中的3个字节数据。
4、Base16——示例
61646D696E
它的特点是没有等号并且数字要多于字母
Base16编码的方式:
1.将数据(根据ASCII编码,UTF-8编码等)转成对应的二进制数,不足8比特位高位补0。然后将所有的二进制全部串起来,4个二进制位为一组,转化成对应十进制数。
2.根据十进制数值找到Base16编码表里面对应的字符。Base16是4个比特位表示一个字符,所以原始是1个字节(8个比特位)刚好可以分成两组,也就是说原先如果使用ASCII编码后的一个字符,现在转化成两个字符。数据量是原先的2倍。
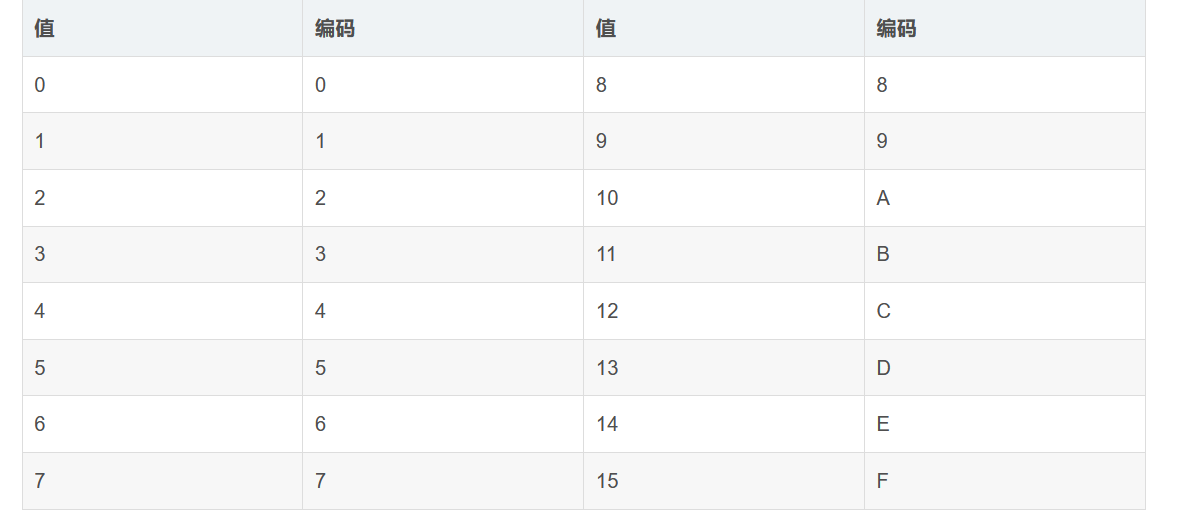
Base16编码是一个标准的十六进制字符串(注意是字符串而不是数值),更易被人类和计算机使用,因为它并不包含任何控制字符,以及Base64和Base32中的“=”符号。

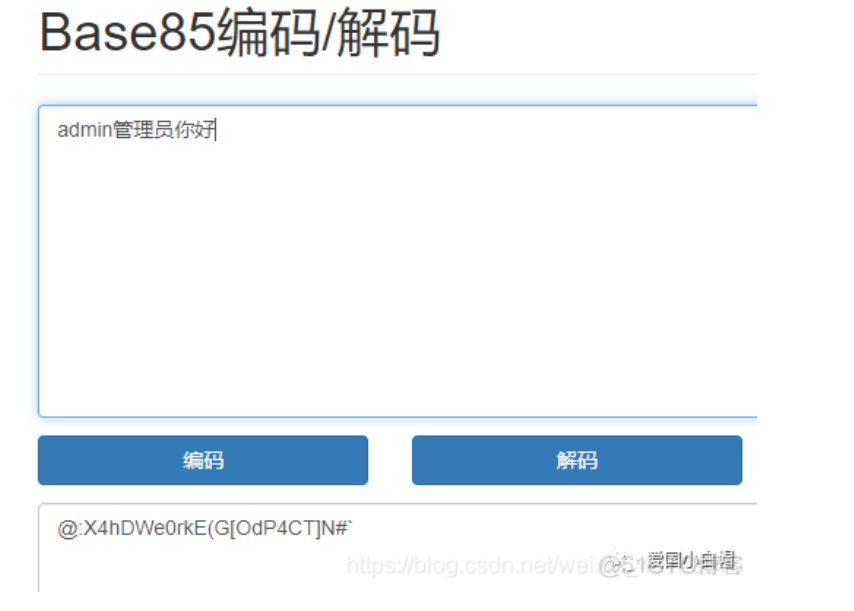
5、Base85——示例
@:X4hDWe0rkE(G[OdP4CT]N#
特点是奇怪的字符比较多,但是很难出现等号
6、Base100——示例
????????????????????
特点就是一堆Emoji表情
Base100编码/解码工具(又名:Emoji表情符号编码/解码),可将文本内容编码为Emoji表情符号;同时也可以将编码后的Emoji表情符号内容解码为文本。

常用解密网站:
Base64:
tool.oschina.net
www.sojson.com
base64.us
Base58:
www.metools.info
Base32、16:
www.qqxiuzi.cn
Base100:
www.atoolbox.net
1、Unicode——汉字示例
1 | 汉字示例这(这);、字母示例t(t);、数字符号示例5(5); |
可以说Unicode与HTML实体编码是一个东西
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。1990年开始研发,1994年正式公布。
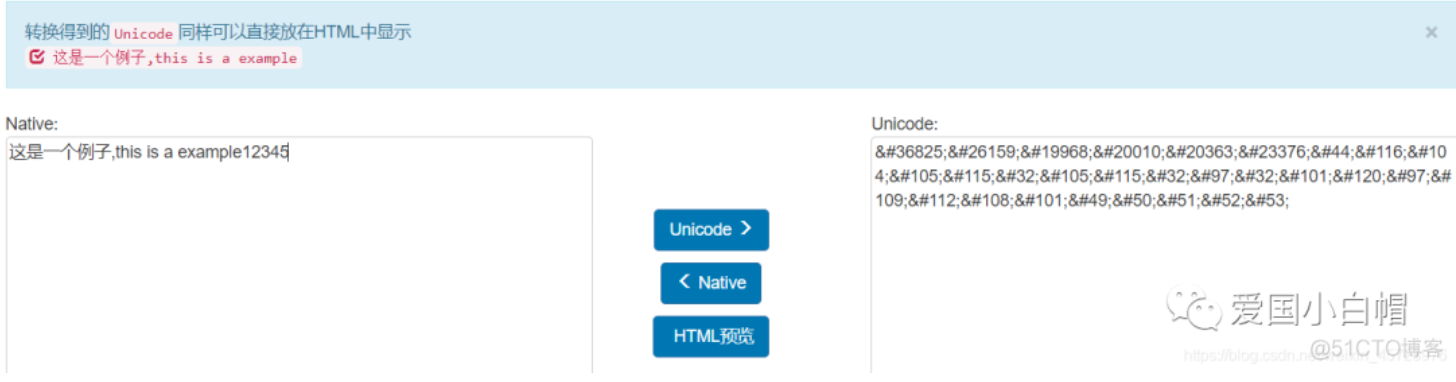
2、HTML实体编码——示例与Unicode相同
字符实体是用一个编号写入HTML代码中来代替一个字符,在使用浏览器访问网页时会将这个编号解析还原为字符以供阅读。
这么做的目的主要有两个:
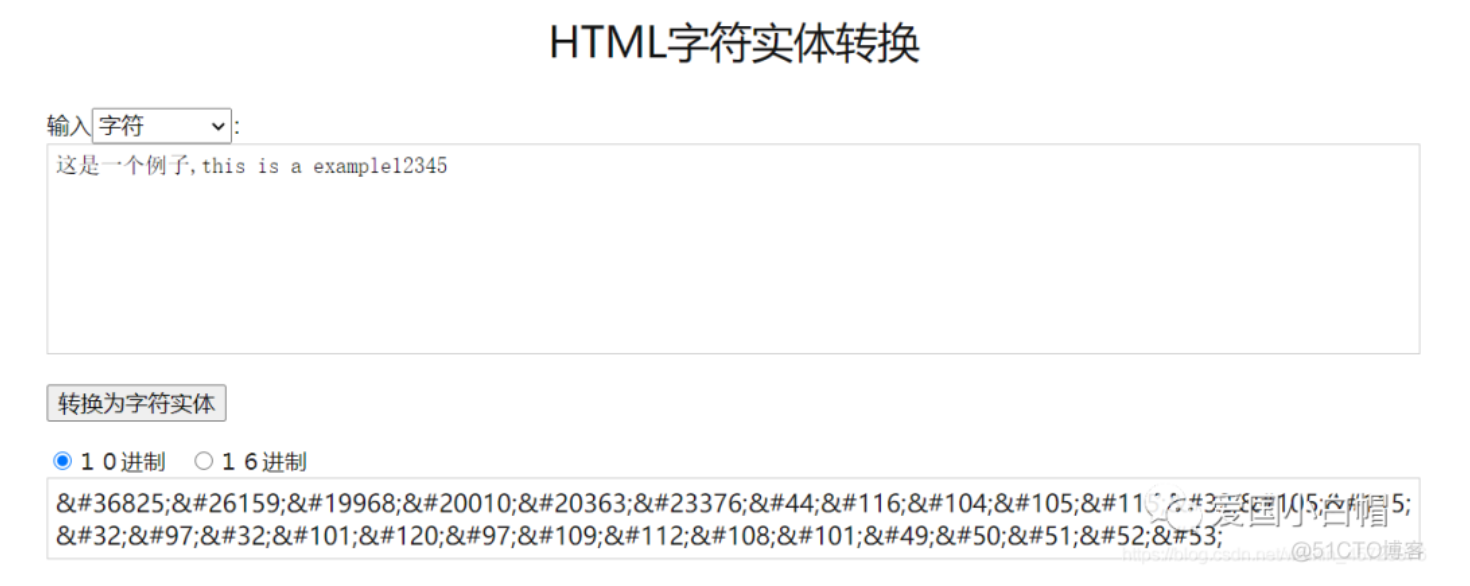
1、解决HTML代码编写中的一些问题。例如需要在网页上显示小于号(<)和大于号(>),由于它们是HTML的预留标签,可能会被误解析。这时就需要将小于号和大于号写成字符实体:
小于号这样写:< 或 <
大于号这样写:> 或 >
前面的写法称为实体名称,后面的写法则是实体编号。ISO-8859-1字符集(西欧语言)中两百多个字符设定了实体名称,而对于其它所有字符都可以用实体编号来代替。
2、网页编码采用了特定语言的编码,却需要显示来自其它语言的字符。例如,网页编码采用了西欧语言ISO-8859-1,却要在网页中显示中文,这时必须将中文字符以实体形式写入HTML代码中。
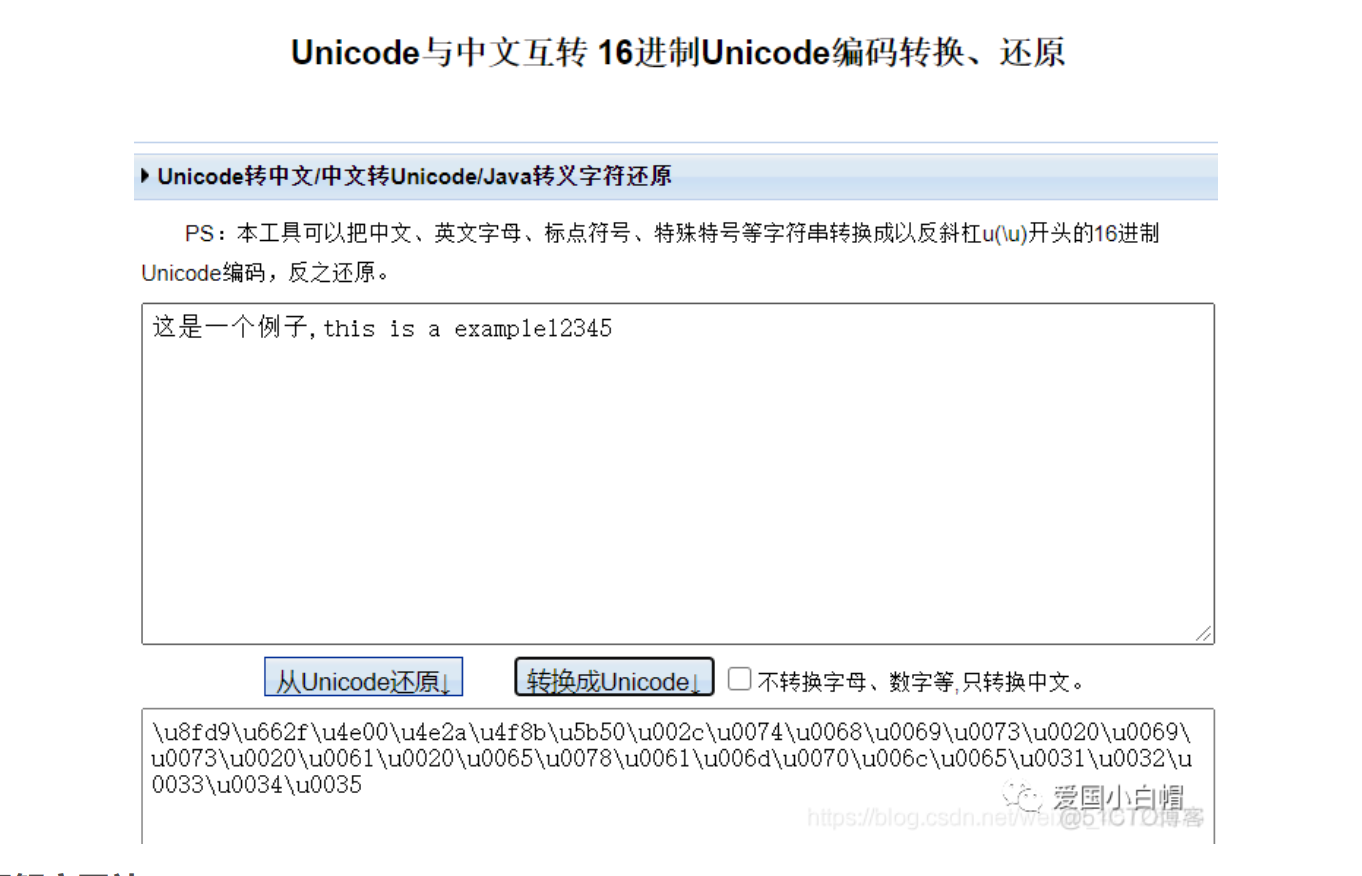
3、16进制Unicode——示例
\u8fd9\u662f\u4e00
常用解密网站:
·Unicode:
www.sojson.com
·16进制Unicode:
www.msxindl.com
·HTML字符实体:
www.qqxiuzi.cn
….还有一些引入密钥的非对称型算法,可以看看原文